
自分好みの日本酒を知りたい
私は日本酒が好きです。しかし、なかなか好きなお酒にめぐり会うことができません。好きな日本酒に出会っても、似たテイストの日本酒を探す方法は知りません。片っ端から日本酒を飲んで、自分の好きな日本酒リストを少しずつ増やしていくしか方法はないのか。いや、この方法だと好きな酒を飲む時間より好きじゃない酒を飲む時間の方が多くなってしまうし、限られた肝機能ももったいない!もっと効率よく探さなければ。。そうだデータサイエンス(AI)を使えば、自分好みの日本酒を探し出せるはずだ!
まずPCAで日本酒の立ち位置をグラフ化してみます。その後は、hierarchical clusteringで日本酒系統樹を作り、好きな日本酒に近いグループを探します。
自分の好きな日本酒
- 真澄 ひやおろし
- 寫楽
- 風の森
- 十四代
これらと似たような感じの日本酒を見つけたい。
日本酒データセット
githubに日本酒データセットがありました。yoichi1484さんの日本酒のデータセット。すばらしいデータセットを提供してくださり感謝です。
sake_dataset. Copyright (c) 2020 Yoichi Ishibashi
Released under the MIT license:https://github.com/yoichi1484/sake_dataset/blob/master/LICENSE.txt
変数は、銘柄、品名、酒造、酒造所在地、特定名称、精米歩合、アルコール度数、日本酒度、酸度、アミノ酸度、甘辛度、米、酵母、造り。
データ解析 R
まずデータがどれくらいあるのか見てみます。
df <- read.csv("SakeDataset.csv", encoding="UTF-8")
length(unique(df$銘柄.品名))
[1] 1287
df <- na.omit(df)
length(unique(df$銘柄.品名))
[1] 7511287種の日本酒データがあるようです。欠損データを除くと751種になってしまいましたが、まだまだありますね。
PCAにて日本酒マッピング
PCAは複数の指標を使って、2次元上に特徴を残したままマッピングする手法です。
精米歩合、アルコール度数、日本酒度、酸度、アミノ酸度、甘辛度の数値を使って、日本酒の立ち位置をマッピングします。
df2 <- df %>% select(X.U.FEFF.銘柄,
銘柄.品名,
精米歩合,
アルコール度数..mean.....,
日本酒度..mean.,
酸度..mean.,
アミノ酸度..mean.,
甘辛度)
colnames(df2) <- c("銘柄",
"品名",
"精米歩合",
"アルコール度数",
"日本酒度",
"酸度",
"アミノ酸度",
"甘辛度")
df3 <- df2 %>% select(-銘柄,-品名)
pca <- prcomp(df3, scale = TRUE)
PCAloadings <- data.frame(Variables = rownames(pca$rotation), pca$rotation)
# Plot
tibble(pc1 = pca$x[,1], pc2 = pca$x[,2], label=df2$品名) %>%
ggplot()+
geom_text(size = 3, aes(x=pc1, y = pc2, label = label, color = (pc1+pc2)),family = "meiryo")+
scale_color_gradientn(colours = c("pink","deeppink","lightskyblue","dodgerblue") )+
geom_segment(data = PCAloadings, aes(x = 0, y = 0, xend = (PC1*10),
yend = (PC2*10)), arrow = arrow(length = unit(1/2, "picas")),
color = "grey30") +
annotate("text", x = (PCAloadings$PC1*11), y = (PCAloadings$PC2*11),
label = PCAloadings$Variables, color = "grey30")+
theme_minimal()+
ggtitle("日本酒PCA分析")+
theme(legend.position = "none",
text=element_text(family = "meiryo"),
plot.title=element_text(hjust=0.5))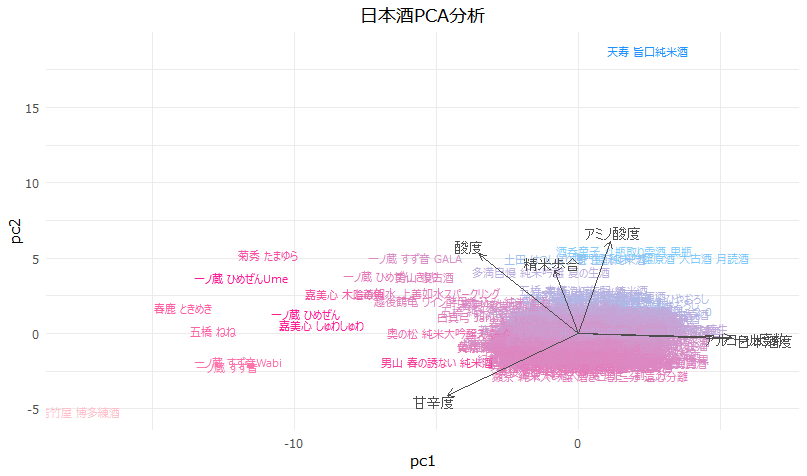
一部の日本酒が特徴的な味を持っていることが分かります。若竹屋 博多錬酒、天寿 旨口純米酒のような酒はかなり特徴的なポジションにいます。博多錬酒は甘辛度がとても高いです。天寿甘口純米酒はアミノ酸度が高いですがどんな味なんでしょうか。興味がわいてきます。
しかし、私が知りたいのは自分の好きな酒に似ている酒です。真澄 ひやおろしはどこかわかりません!2次元では、私の好きな特徴が捉えられなかったみたいです。
Hierarchical clustering
日本酒のクラスターを作ります。
library(factoextra)
df2 <- df %>% select(X.U.FEFF.銘柄,
銘柄.品名,
精米歩合,
アルコール度数..mean.....,
日本酒度..mean.,
酸度..mean.,
アミノ酸度..mean.,
甘辛度)
colnames(df2) <- c("family",
"name",
"riceratio",
"alchol",
"ricewinedegree",
"acidity",
"aminoacid",
"sweetdry")
df4 <- df2 %>% select(-family)
df4 <- df4 %>% filter(!duplicated(name))
row.names(df4) <- df4$name
df4 <- df4 %>% select(-name,-ricewinedegree,-sweetdry)
d <- dist(df4)
clusters <- hclust(d,
method = "complete")
fviz_dend(
clusters,
horiz = TRUE,
cex = 0.1
)+theme(legend.position = "none")+
ggtitle("日本酒 クラスター")+
theme(text = element_text(family = "meiryo"))
うっ、思ってたのとなんか違う。ズームしても細かすぎてわからない・・・。
真澄 ひやおろしの所属するクラスターがみたいんだけどどこにあるのか。
ターゲットクラスターにズーム!
真澄 純米吟醸 ひやおろしのクラスターを知りたい。同じクラスターは似たテイストを持っているはずだ。
target.label <- "真澄 純米吟醸 ひやおろし"
h.val <- 1
ct <- cut(as.dendrogram(clusters), h.val)$lower
flag <- FALSE
leaf.len <- 1
for(i in 1:length(ct)) {
if(is.leaf(ct[[i]])) {
if(target.label == labels(ct[[i]])) {
flag <- TRUE
leaf.len <- 1
break
}
} else {
ct.leafs <- cut(ct[[i]], h=0)$lower
leaf.len <- length(ct.leafs)
for(j in 1:leaf.len) {
if(!is.na(match(target.label, labels(ct.leafs[[j]])))) {
flag <- TRUE
break
}
}
}
if(flag) break
}
fviz_dend(
ct[[i]],
k = 3,
horiz = TRUE,
rect = TRUE,
font.family = "meiryo")+
ggtitle("真澄 純米吟醸ひやおろしに近いグループ")+
theme(text = element_text(family = "meiryo"))上記のアルゴリズムはこちらのブログ(METOOL)を参考にさせていただきました。
できました!
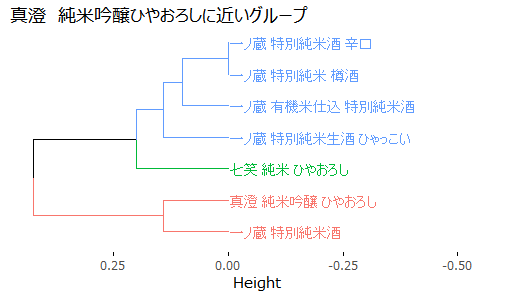
一ノ蔵 特別純米酒が、一番近い仲間だとわかりました。
さっそく注文。楽しみです!!