
コレスポンデンス分析(CA: Correspondence Analysis)
コレスポンデンス分析は、PCAと似た目的を持っています。アンケート等の多次元のカテゴリ変数を、低次元に落とし込んで傾向を見つけやすくする手法です。PCAと異なる点は、PCAは連続変数に対して実施するのに対して、CAはカテゴリ変数に対して実施します。
PCAよりも格段に理論が難しいです。PCAの第1軸が、CAではイナーシャinertiasというものになります。PCAと同じように軸ごとに蓄積情報量を見ることができます。CAは、類似性を保ちながら低次元に落とし込む計算をしているようです。正直なところ数学的な処理が理解できていません。
ただ、すごく簡単に使えますし便利です。グラフを低次元に落とし込んで傾向を掴むことは非常に有用だと思います。マーケティングでは、商品A商品B等の性質に関するアンケートの解析に使い、製品同士のグルーピング化に活用しているようです。グルーピング化自体は、kmeans、hierarchical classificationとかあるから、組み合わせればうまく解析できそうですね。
今回は、農水省の実施した学生アンケート結果を使用します。
https://www.maff.go.jp/j/council/zyuizi/keikaku/h30_1/attach/pdf/shiryo-7.pdf
各職業分野の意識が各項目について質問されています。
- 給与が高い
- 業務内容が面白い
- 業務内容の社会的貢献度が高い
- 業務内容の身体的負担が少ない
- 業務内容を通じて成長できる
- 業務上の人間関係にストレスが少ない
- 残業・休日出勤が少なく、自分の時間が多く持てる
- 産休等福利厚生が充実している
- その分野に将来性がある

このデータを用いて、コレスポンデンス分析をRで実施したいと思います。
まず手で実数をエクセルに保存します。列にカテゴリ変数をいれてください。

データの読み込みをします。1列目を、行名としたいです。そのため、row.nameで、1列目を行名にしています。その後、1列目を除いています。
χ二乗テストを実施して、それぞれの変数は独立であることをテストします。変数の割合が全く同じである確率がp-value < 2.2e-16なので、割合は同じではありません。職業によって、イメージが異なることがわかります。
library(tidyverse)
df <- read.csv("ca.csv")
row.names(df) <- df$categories
df <- df %>% select(-categories)
chisq.test(df)さっそくコレスポンデンス分析を実施して、グラフ化します。caというパッケージを利用します。
library(ca)
ca_obj <- ca(df)
plot(ca_obj)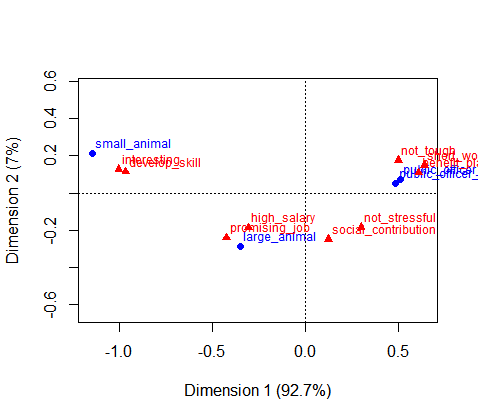
第1次元だけで、93%も説明できているのでうまくいきました。統計量を見てみます。
summary(ca_obj)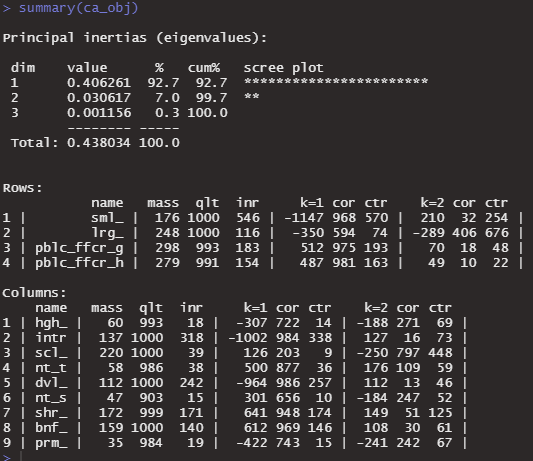
上のintertiasは、わかる。PCAと同じように見れるから。その下が難しい。。
cor: Squared correlations
ctr: contributions
qlt: The total quality (qlt)
ちなみに、ggplotで描写するとこんな感じになります。ラベルが重なってしまうのが嫌なので、ggrepelを使っています。geom_textのところを、geom_text_repelとするだけでラベルを重ならないようにしてくれます。
第1次元の座標は、ca_obj$rowcoord[, 1]*ca_obj$sv[1], ca_obj$colcoord[,1]*ca_obj$sv[1]、で計算できます。
biplot_data <- tibble(variable = c(rownames(ca_obj$rowcoord),rownames(ca_obj$colcoord)),
d1 = c(ca_obj$rowcoord[,1]*ca_obj$sv[1],ca_obj$colcoord[,1]*ca_obj$sv[1]),
d2 = c(ca_obj$rowcoord[,2]*ca_obj$sv[2],ca_obj$colcoord[,2]*ca_obj$sv[2]),
color = c(rep("blue",length(rownames(ca_obj$rowcoord))),
rep("red",length(rownames(ca_obj$colcoord)))))
library(ggrepel)
biplot_data %>%
ggplot()+
geom_point(aes(x=d1,y=d2,color=color,shape=color),size=5)+
geom_hline(yintercept = 0,color="grey")+
geom_vline(xintercept = 0,color="grey")+
geom_text_repel(aes(x=d1,y=d2,label=variable,color=color),max.overlaps=20)+
xlab("Dimention 1")+
ylab("Dimention 2")+
theme_minimal()+
xlim(-1.2,1.2)+
ylim(-0.3,0.3)+
theme(legend.position = "none")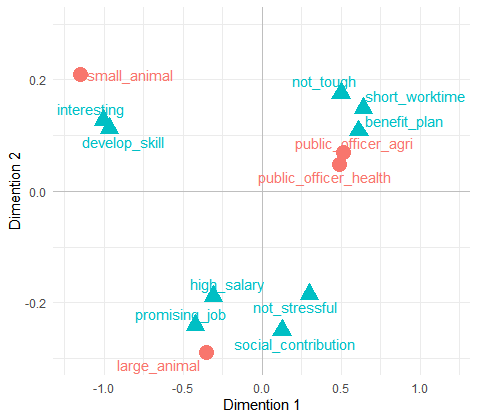
グラフを見ると、小動物と、大動物と、公務員と大きく分かれることがわかりました。小動物は、楽しい・成長できる。大動物は、将来有望・社会的貢献度が高い等、公務員は、身体的につらくない・福利厚生がしっかりしている。といった感じでしょうか。
PCAもそうですが、CAも軸の解釈は解析者にゆだねられています。どうしましょうか。第1軸のx軸はやりがい軸、第2軸のy軸はお金と身体負担の兼ね合い軸といったところでしょうか。