
以前、麻酔モニター自動記録装置をOCRを使って作成しました。
しかし、デジタル数字だとtessoractOCRの精度が上がらずに正確な数値がでないことがありました。
別の方法として、Convolutional Neural Networkを使って画像の分別をする方法があります。ただ、この方法は1桁の数字だけが映っている画像を要求します。(Regional Convolutional Neural Networkでもできるのでしょうか。)そのため、画像加工してモニター全体の画像から数字のみ映っている画像を作り出す必要があります。
数字の映っている場所の座標を知っていればアフィン変換を実施することで数字のみの画像を作ることができます。
座標を知る方法は以下の2つです。
①マニュアルで座標の位置を調べる
②自動で座標の位置を取得する
以前の記事で関心領域の座標を自動で取得する試みを行いましたが、結局マーカーを設置することが一番の近道だと判明しました。
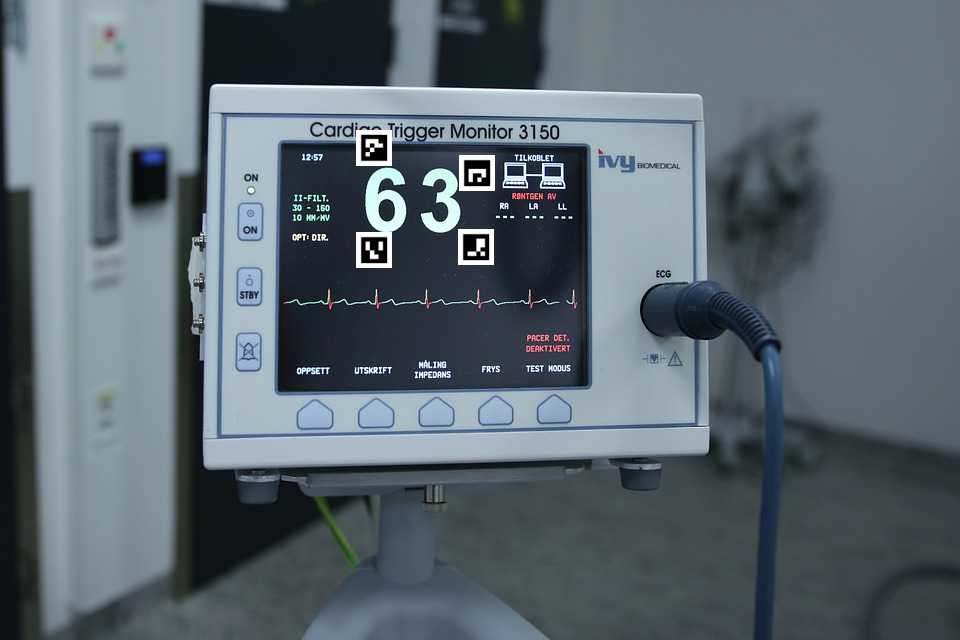
今回は、実際の麻酔モニターの画像中にArUcoマーカーを配置してアフィン変換できるかどうか確認してみます。
モニター画像は、クリエイティブコモンズ検索で見つけたものです。
モニターにArUcoマーカーを貼り付けて撮影したと仮定します。
まずは、ArUcoマーカーを作成するところから始めます。pythonでopencvを使って作成します。マーカーがフォルダに保存されます。
import cv2
aruco = cv2.aruco
arco_dict = aruco.getPredefinedDictionary(aruco.DICT_4X4_50)
for i in range(4): #4は作成するマーカー数
arco_img = aruco.drawMarker(arco_dict, i, 75) #75 pixel
img_pad = cv2.copyMakeBorder(arco_img, 15, 15, 15, 15, cv2.BORDER_CONSTANT, value=(255,255,255))
cv2.imwrite(f"C:\\Users\\marker{i}.png", img_pad)2行目は、cv2.arucoのオブジェクトを作成します
3行目は、arucoマーカーの辞書を呼び出します
4行目は、loopで辞書から1つづつ呼び出します。rangeの中の数字を変えることで作成するマーカーの数を変えることができます。
5行目は、ピクセルサイズを指定しマーカーを作ります
6行目は、画像の周りに白い枠を作ります。パディングです。
7行目は、マーカーの書き出しをします。
6行目(パディング)の必要性について
パデングなしだと、以下のような画像になります。黒い縁が画像の端っこです。

これだと、モニターの背景が黒いのでマーカーが認識されずらいです。そのため、画像の周りに白い枠を付ける必要があります。それがパディングです。
麻酔モニター中のarucoマーカーを特定する
特定のためのコード
corners, ids, __ = aruco.detectMarkers(img, aruco_dict)
入力
画像
arucoマーカーを作成したときのaruco辞書
出力
corners:マーカーの4点の座標を持っています。左上から時計回りの順番です。
ids:cornersに入っている座標の順番と、アルコマーカーのidをリンクさせる情報を持っています。
aruco.drawDetectedMarkersは、マーカーの周りに情報を書くコードです。
import numpy as np
img = cv2.imread(r"C:\Users\monitor_aruco.jpg")
corners, ids, __ = aruco.detectMarkers(img, arco_dict)
img_marked = aruco.drawDetectedMarkers(img.copy(), corners, ids)
cv2.imshow('image',img_marked)
cv2.waitKey()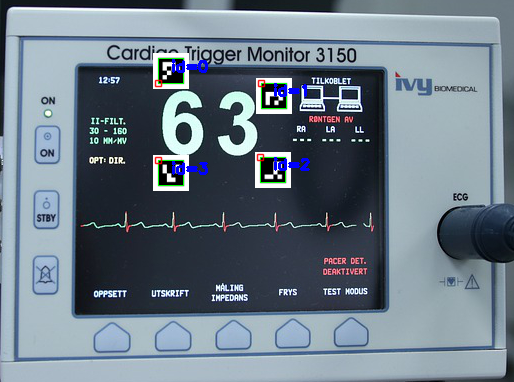
マーカーのidは、左上から時計回りに0、1、2、3です。マーカーには上下左右があるので、設置の仕方に注意です。それぞれのマーカーの左上を、知りたい座標の場所に設置しています。
idsとcornersの変数の中身は以下の通りです。
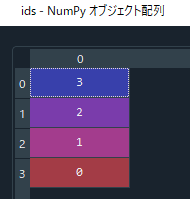
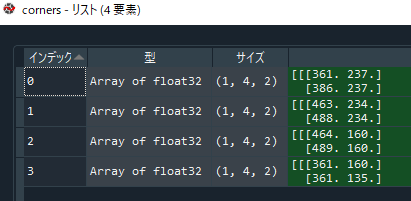
マーカーの座標を取得します。
ndarrayの関係で階層構造を取り除くために[0][0]を付けています。
index_0 = np.where(ids == 0)[0][0]
index_1 = np.where(ids == 1)[0][0]
index_2 = np.where(ids == 2)[0][0]
index_3 = np.where(ids == 3)[0][0]
corner_0 = corners[index_0][0][0]
corner_1 = corners[index_1][0][0]
corner_2 = corners[index_2][0][0]
corner_3 = corners[index_3][0][0]
print(corner_0)
print(corner_1)
print(corner_2)
print(corner_3)[361. 160.] [464. 160.] [463. 234.] [361. 237.]
座標を取り出せました。
うまく取れているか確認のため、4点の座標を使って台形を書いてみたいと思います。精確な長方形でないためcv2.rectangleを使っていません。cv2.rectangleは2点のみ指定できます。
台形を書くため少し複雑そうなコードになっていますが、台形の4点座標を設定しているのが1行目です。
pts = np.array([corner_0,corner_1,corner_2,corner_3], np.int32)
pts = pts.reshape((-1,1,2))
img8 = cv2.polylines(img.copy(),[pts],True,(0,255,255))
cv2.imshow('image',img8) # 表示
cv2.waitKey()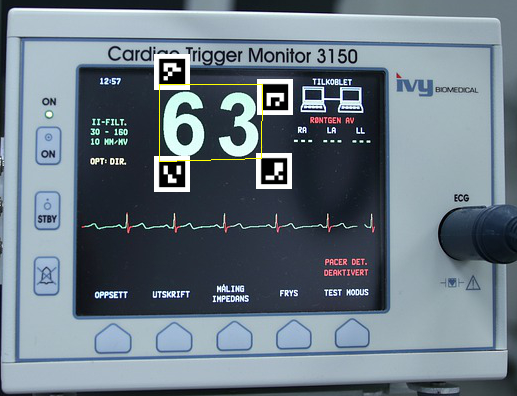
うまく切り出せそうなので、いよいよアフィン変換を実施したいと思います。
最初の4行でaffine変換しています。画像のアスペクト比が元の画像になっているので、5行目でresizeを実施しています。
1行目は、先ほど入手した座標をセットしています。
2行目は、元の画像の端の座標をセットしています。
3行目は、affine変換を計算するための行列を作っています。
4行目は、affine変換を行っています。
src_points = np.float32([[corner_0,corner_1,corner_3,corner_2]])
dst_points = np.float32([[0,0], [img.shape[0],0], [0,img.shape[1]], [img.shape[0],img.shape[1]]])
projective_matrix = cv2.getPerspectiveTransform(src_points, dst_points)
img_output = cv2.warpPerspective(img.copy(), projective_matrix, (img.shape[0],img.shape[1]))
halfImg = cv2.resize(img_output, (500,300))
cv2.imshow('image',halfImg)
cv2.waitKey()
ArUcoマーカーの白いところが邪魔ですが、この画像を一杯用意してCNNに覚えさせれば白いところは無視されるようになるので大丈夫だと思います。
以下の記事で数字判別のAIの作り方を書いています。