
最初に
興味深いデータセットを見つけました。離婚した夫婦と、離婚していない夫婦のデータです。離婚した夫婦は、どういった点に特徴があったのかをAIで分析し、夫婦関係の維持に大事なことを学びたいと思います。
具体的には、neural network、Adaboost、gradient boost machine、random forest、logistic regression、support vector machineを使って解析します。
このデータは、トルコの150組の夫婦から得られました。回答は、離婚したカップルや幸せな結婚生活を送っているカップルの対面式インタビューから得られました。質問は54個あり、すべての回答は5段階評価(0=まったくない、1=めったにない、2=普通、3=よくある、4=いつもある)で収集されました。
https://www.kaggle.com/andrewmvd/divorce-prediction
補足説明:https://archive.ics.uci.edu/ml/datasets/Divorce+Predictors+data+set#
引用:Yöntem, M , Adem, K , İlhan, T , Kılıçarslan, S. (2019). DIVORCE PREDICTION USING CORRELATION BASED FEATURE SELECTION AND ARTIFICIAL NEURAL NETWORKS. Nevşehir Hacı Bektaş Veli University SBE Dergisi, 9 (1), 259-273. Retrieved from [Web Link]
解析
上記のkaggleのデータをダウンロードしました。
df = pd.read_csv("/content/divorce_data.csv",delimiter=";")
df
質問が54あり、0~4で回答されています。最後の列に離婚したかどうかが0か1かで表現されています。1が離婚と説明されています。(後で述べますが、質の怪しいデータセットです)
Autokerasでneural networkを使ってカテゴリ予測します。
!pip install -q autokeras
import autokeras as ak
import numpy as np
data = pd.read_csv("/content/divorce_data.csv",delimiter=";")
# list of random index
mylist = np.random.choice(np.arange(len(data)), len(data),
replace=False)
id_train = mylist[: int(len(data)*0.8)]
id_test = mylist[-int(len(data)*0.2):]
# train data
x_train = data.iloc[id_train.tolist(),]
y_train = x_train.pop("Divorce")
y_train = pd.DataFrame(y_train)
x_train = x_train.to_numpy()
y_train = y_train.to_numpy()
# test data
x_test = data.iloc[id_test.tolist(),]
y_test = x_test.pop("Divorce")
y_test = pd.DataFrame(y_test)
x_test = x_test.to_numpy()
y_test = y_test.to_numpy()
# autokerasは結果にばらつきがあるので、一番いいやつを選ぶ
maxacc = 0
for i in range(20):
clf = ak.StructuredDataClassifier(overwrite=False, max_trials=30)
history = clf.fit(x_train, y_train, epochs=30,validation_split=0.2)
result = clf.evaluate(x_test, y_test)
if result[1] > maxacc:
model_autokeras = clf.export_model()
model_autokeras.save("/content/autokeras",save_format="tf")
maxacc = result[1]
print("saved",result)
else:
continuetestデータでの精度を見てみます。
from tensorflow.keras.models import load_model
from sklearn.metrics import accuracy_score
manual = load_model("/content/autokeras")
print("manual",manual.evaluate(x_test, y_test))
t = (manual.predict(x_test)>0.5)*1
flat_list = []
for sublist in t:
for item in sublist:
flat_list.append(item)
print(accuracy_score(np.array(flat_list),y_test))manual [0.020938992500305176, 1.0]
精度100%がでました。さすが、neural network。しかし、予測はできるもののどの質問が重要なのか分かりません。これでは勉強にならないので、要素の重要性を計算できる他の方法で機械学習させます。
random forest、grandient boost machine、Adaboost、logistic regression、support vector machineを使ってみます。logistic regressionとsupport vector machineはオマケです。
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier,AdaBoostClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
clf_rf = RandomForestClassifier()
clf_rf.fit(x_train, y_train.ravel())
print(accuracy_score(clf_rf.predict(x_test),y_test.ravel()))
clf_gbc = GradientBoostingClassifier()
clf_gbc.fit(x_train, y_train.ravel())
print(accuracy_score(clf_gbc.predict(x_test),y_test.ravel()))
clf_ada = AdaBoostClassifier()
clf_ada.fit(x_train, y_train.ravel())
print(accuracy_score(clf_ada.predict(x_test),y_test.ravel()))
from sklearn.linear_model import LogisticRegression
clf_logi = LogisticRegression(random_state=0).fit(x_train, y_train.ravel())
print(accuracy_score(clf_logi.predict(x_test),y_test.ravel()))
from sklearn.svm import SVC
clf_svc = SVC(gamma="scale").fit(x_train,y_train.ravel())
print(accuracy_score(clf_svc.predict(x_test),y_test.ravel()))Accuracyのスコアです。
0.9117647058823529 RandomForestClassifier
0.9411764705882353 GradientBoostingClassifier
0.8823529411764706 AdaBoostClassifier
0.9117647058823529 logistic regression
0.9117647058823529 support vector machine
random forest、grandient boost machine、Adaboostについては、要素の重要度が計測できます。重要度のスケールがそれぞれ異なるので、質問の重要度のランキングの平均を使って、一番大事な質問はどれかを探しました。
importance_rf = clf_rf.feature_importances_
importance_gbc = clf_gbc.feature_importances_
importance_ada = clf_ada.feature_importances_
resultdf = pd.DataFrame(columns=["Qestion","Importance_rf","Importance_gbc","Importance_ada"],index = range(len(importance_rf)))
for i, feat in enumerate(df2.columns[:-1]):
resultdf.iloc[i,0] = feat
resultdf.iloc[i,1] = importance_rf[i]
resultdf.iloc[i,2] = importance_gbc[i]
resultdf.iloc[i,3] = importance_ada[i]
resultdf["Importance_rf"] = resultdf["Importance_rf"].astype(float)
resultdf["Importance_gbc"] = resultdf["Importance_gbc"].astype(float)
resultdf["Importance_ada"] = resultdf["Importance_ada"].astype(float)
resultdf["rank_rf"] = resultdf["Importance_rf"].rank(ascending=False)
resultdf["rank_gbc"] = resultdf["Importance_gbc"].rank(ascending=False)
resultdf["rank_ada"] = resultdf["Importance_ada"].rank(ascending=False)
resultdf["mean"] = resultdf.iloc[:,4:7].mean(axis=1)
resultdf = resultdf.sort_values(by = "mean",ascending=True)
resultdf.head()
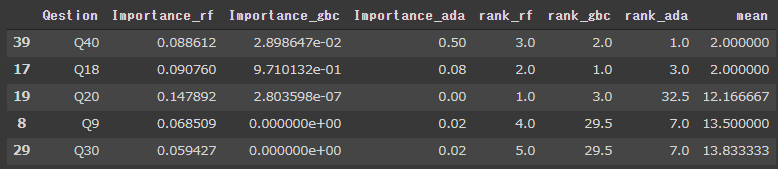
Q40とQ18が大事だとわかりました。しかし、この結果はコードを実行するごとに変わってしまいます。100回試行してみます。
data = pd.read_csv("/content/divorce_data.csv",delimiter=";")
mostimportantqestion = pd.DataFrame(0,columns=["Q"],index=range(100))
for j in range(100):
mylist = np.random.choice(np.arange(len(df2)), len(df2), replace=False)
id_train = mylist[: int(len(df2)*0.8)]
id_test = mylist[-int(len(df2)*0.2):]
# train
x_train = data.iloc[id_train.tolist(),]
y_train = x_train.pop("Divorce")
y_train = pd.DataFrame(y_train)
x_train = x_train.to_numpy()
y_train = y_train.to_numpy().ravel()
# Preparing testing data.
x_test = data.iloc[id_test.tolist(),]
y_test = x_test.pop("Divorce")
y_test = pd.DataFrame(y_test)
x_test = x_test.to_numpy()
y_test = y_test.to_numpy().ravel()
clf_rf = RandomForestClassifier()
clf_rf.fit(x_train, y_train)
clf_gbc = GradientBoostingClassifier()
clf_gbc.fit(x_train, y_train)
clf_ada = AdaBoostClassifier()
clf_ada.fit(x_train, y_train)
from sklearn.linear_model import LogisticRegression
clf_logi = LogisticRegression(random_state=0).fit(x_train, y_train)
from sklearn.svm import SVC
clf_svc = SVC(gamma="scale").fit(x_train,y_train)
importance_rf = clf_rf.feature_importances_
importance_gbc = clf_gbc.feature_importances_
importance_ada = clf_ada.feature_importances_
resultdf = pd.DataFrame(columns=["Qestion","Importance_rf","Importance_gbc","Importance_ada"],index = range(len(importance_rf)))
for i, feat in enumerate(df2.columns[:-1]):
resultdf.iloc[i,0] = feat
resultdf.iloc[i,1] = importance_rf[i]
resultdf.iloc[i,2] = importance_gbc[i]
resultdf.iloc[i,3] = importance_ada[i]
resultdf["Importance_rf"] = resultdf["Importance_rf"].astype(float)
resultdf["Importance_gbc"] = resultdf["Importance_gbc"].astype(float)
resultdf["Importance_ada"] = resultdf["Importance_ada"].astype(float)
resultdf["rank_rf"] = resultdf["Importance_rf"].rank(ascending=False)
resultdf["rank_gbc"] = resultdf["Importance_gbc"].rank(ascending=False)
resultdf["rank_ada"] = resultdf["Importance_ada"].rank(ascending=False)
resultdf["mean"] = resultdf.iloc[:,4:7].mean(axis=1)
resultdf = resultdf.sort_values(by = "mean",ascending=True)
mostimportantqestion.iloc[j,0]=resultdf.iloc[0,0]
print(mostimportantqestion["Q"].value_counts())Q40 43 Q18 34 Q26 11 Q17 4 Q11 3 Q19 3 Q9 1 Q20 1
Q40が1番重要となった回数が43回、Q18が1番重要だったのが34回、Q26が1番だったのが11回です。
Q40
We’re just starting a discussion before I know what’s going on.
何が起こっているのかわからないうちに、議論を始めているところです。
ちょっと意味がわからないです。英語力の問題?なんでもすぐに相談しろってところでしょうか?
気を取り直してQ18はなんでしょうか。Q18:私と配偶者は、結婚のあり方について同じような考えを持っています。
これは大事そうです。
Q26は?私は配偶者の基本的な不安を知っています。
相手の不安ごとを知っていることは大事ですね。
学んだこと
夫婦関係を維持するのには、以下の項目が重要だとわかりました
- すぐ相談する
- 結婚の在り方について共通認識を持つ
- 相手の不安について理解しておく
ところで質問54個しなくても、重要な3つの質問だけでも予測できるのでしょうか。やってみます。
!pip install -q dfply
from dfply import *
df3 = df2 >> select(X["Q40"],X["Q18"],X["Q26"], X["Divorce"])
mylist = np.random.choice(np.arange(len(df3)), len(df3), replace=False)
id_train = mylist[: int(len(df3)*0.8)]
id_test = mylist[-int(len(df3)*0.2):]
data = df3
# train
x_train = data.iloc[id_train.tolist(),]
y_train = x_train.pop("Divorce")
y_train = pd.DataFrame(y_train)
x_train = x_train.to_numpy()
y_train = y_train.to_numpy()
# Preparing testing data.
x_test = data.iloc[id_test.tolist(),]
y_test = x_test.pop("Divorce")
y_test = pd.DataFrame(y_test)
x_test = x_test.to_numpy()
y_test = y_test.to_numpy()
maxacc = 0
for i in range(20):
clf2 = ak.StructuredDataClassifier(overwrite=False, max_trials=30)
history = clf2.fit(x_train, y_train, epochs=30,validation_split=0.2)
result = clf2.evaluate(x_test, y_test)
print(result)
if result[1] > maxacc:
model_autokeras = clf2.export_model()
model_autokeras.save("/content/autokeras2",save_format="tf")
maxacc = result[1]
print("saved",result)
else:
continue
manual = load_model("/content/autokeras2")
print("manual",manual.evaluate(x_test, y_test))
t = (manual.predict(x_test)>0.5)*1
flat_list = []
for sublist in t:
for item in sublist:
flat_list.append(item)
print(accuracy_score(np.array(flat_list),y_test))manual [0.27838268876075745, 0.9411764740943909]
accuracyは0.94と少し下がりました。(質問54個つかうと1)
他の機械学習モデルはどうでしょうか。
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier,AdaBoostClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import accuracy_score
clf_rf = RandomForestClassifier()
clf_rf.fit(x_train, y_train.ravel())
print(accuracy_score(clf_rf.predict(x_test),y_test))
clf_gbc = GradientBoostingClassifier()
clf_gbc.fit(x_train, y_train.ravel())
print(accuracy_score(clf_gbc.predict(x_test),y_test))
clf_ada = AdaBoostClassifier()
clf_ada.fit(x_train, y_train.ravel())
print(accuracy_score(clf_ada.predict(x_test),y_test))
from sklearn.linear_model import LogisticRegression
clf_logi = LogisticRegression(random_state=0).fit(x_train, y_train.ravel())
print(accuracy_score(clf_logi.predict(x_test),y_test))
from sklearn.svm import SVC
clf_svc = SVC(gamma="scale").fit(x_train,y_train.ravel())
print(accuracy_score(clf_svc.predict(x_test),y_test))1.0
1.0
1.0
1.0
1.0
全部、100%正解できるようになりました。3つの質問だけで十分なんですね。
Q40を詳しくみてみます。
pd.crosstab(df["Divorce"],df["Q40"])
We’re just starting a discussion before I know what’s going on.
あれ、Divorce1が離婚ですよね?すぐ相談できる夫婦の方が、いいんじゃないのかな。(0=まったくない、1=めったにない、2=普通、3=よくある、4=いつもある)
Q26も見てみます。Q26:私と配偶者は、結婚のあり方について同じような考えを持っています。
pd.crosstab(df["Divorce"],df["Q26"])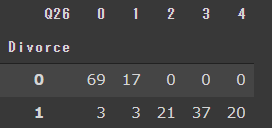
同じ考え方を持っていない方が、離婚しないのか。なんかおかしい気がします。
データを信頼していたので、EDAをやっていませんでした。EDAは初めにやるべきでした。
rader chartを作ってみます。
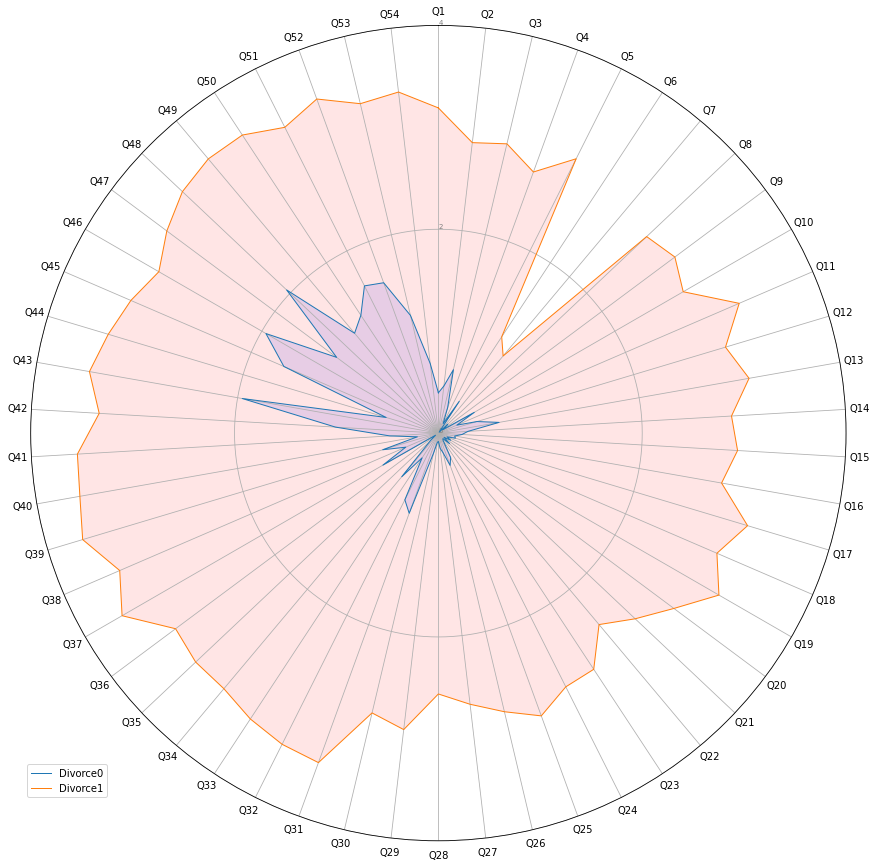
divorce1が離婚夫婦ですが、色々な質問においてスコア高いです。なんかおかしいデータですね。
- 議論が悪化したときに、どちらかが謝れば、その議論は終わります。
- 時には辛いことがあっても、お互いの違いを無視できることを知っている。
- 必要なときには、配偶者との話し合いを最初から受け止めて修正することができる。
- 配偶者と話し合ったとき、彼に連絡することは結局うまくいく。
- 妻と過ごした時間は、私たちにとって特別なものだ。
- 家ではパートナーとしての時間がない。
- 私たちは家族というより、家で同じ環境を共有する他人同士のようだ。
- 休日は妻と一緒に楽しんでいる。
- 妻との旅行は楽しい。
- 私たちの目標のほとんどは、配偶者と共通である。
- 将来、ある日振り返ったときに、配偶者と私が調和していたことがわかると思う。
- 私の配偶者と私は、個人の自由という点で同じような価値観を持っている。
- 私の配偶者と私は、娯楽に対する感覚が似ている。
- 人(子供、友人など)に対する目標のほとんどが同じである。
- 配偶者との夢は似ていて調和がとれている。
- 愛がどうあるべきかについて、配偶者とは相性がいい。
- 私たちは、配偶者との生活で幸せになることについて、同じ見解を持っている
- 結婚はどうあるべきかについて、配偶者と考えが似ている
- 私の配偶者と私は、結婚生活における役割のあり方について、同じような考えを持っている。
- 私の配偶者と私は、信頼における価値観が似ている。
- 私は妻の好みをよく知っている。
- 配偶者が病気になったとき、どのように面倒を見てもらいたいか知っている。
- 私は配偶者の好きな食べ物を知っている。
- 配偶者が生活の中でどのようなストレスを抱えているかわかる。
- 自分の配偶者の内面を知っている。
- 私は配偶者の基本的な不安を知っている。
- 私は、配偶者の現在のストレスの原因が何かを知っている。
- 私は、配偶者の希望や願いを知っている。
- 私は配偶者のことをよく知っている。
- 配偶者の友人やその交友関係を知っている。
- 私は配偶者と議論するとき、攻撃的な気分になる。
- 私は配偶者と議論するとき、「あなたはいつも」や「あなたは決して」などの表現を使うことが多い。
- 私は、話し合いの時に、配偶者の性格について否定的な発言をすることがある。
- 私は、話し合いの時に、攻撃的な表現を使うことができる。
- 私は、話し合いの中で配偶者を侮辱することができる。
- 私は、話し合いの時に屈辱的な態度をとることができる。
- 私の配偶者との話し合いは穏やかではない。
- 私は配偶者の話題の切り出し方が嫌いだ。
- 私たちの議論は突然起こることが多い。
- 何が起こっているのかわからないうちに、議論が始まってしまう。
- 配偶者に何かを相談すると、急に冷静さが崩れます。
- 私の配偶者と議論するとき、ıだけが出て、私は何も言いません。
- 私はほとんど、環境を少しでも落ち着かせるために黙っています。
- たまには、しばらく家を出るのもいいかなと思います。
- 配偶者と議論するよりも、黙っていたい。
- 議論の中で自分が正しくても、配偶者を傷つけるために沈黙してしまう。
- 配偶者と議論するとき、怒りを抑えられないのが怖くて、黙っている。
- 私は議論の中で正しいと感じている。
- 私が非難されたこととは何の関係もない。
- 私が非難されていることについて、実際には私は罪を犯している者ではない。
- 家庭内の問題について、私が間違っているわけではありません。
- 自分の配偶者に自分の不甲斐なさを伝えることを躊躇しない。
- 議論するときは、配偶者に自分の不十分さを思い出させる。
- 私は自分の配偶者に彼女/彼の無能さを伝えることを恐れない。
Divorce0のグループと、Divorce1のグループで点数が違いすぎます。ポジティブな質問についても、離婚グループの方が良い方向で答えているものが多くみられます。これは、相当データの質が悪いと思われます。。
rader chartを作ったコードは以下です。なんてめんどくさいコードなんでしょうか。plotnineにはcoord_polarがないのが残念です。
colnames = list(df.columns)
eda = df.groupby(by = "Divorce").mean()
eda = eda.reset_index()
# Libraries
import matplotlib.pyplot as plt
import pandas as pd
from math import pi
# Set data
df = pd.DataFrame({
'group': ['Divorce0','Divorce1'],
'Q1': eda["Q1"].tolist(),
'Q2': eda["Q2"].tolist(),
'Q3': eda["Q3"].tolist(),
'Q4': eda["Q4"].tolist(),
'Q5': eda["Q5"].tolist(),
'Q6': eda["Q6"].tolist(),
'Q7': eda["Q7"].tolist(),
'Q8': eda["Q8"].tolist(),
'Q9': eda["Q9"].tolist(),
'Q10': eda["Q10"].tolist(),
'Q11': eda["Q11"].tolist(),
'Q12': eda["Q12"].tolist(),
'Q13': eda["Q13"].tolist(),
'Q14': eda["Q14"].tolist(),
'Q15': eda["Q15"].tolist(),
'Q16': eda["Q16"].tolist(),
'Q17': eda["Q17"].tolist(),
'Q18': eda["Q18"].tolist(),
'Q19': eda["Q19"].tolist(),
'Q20': eda["Q20"].tolist(),
'Q21': eda["Q21"].tolist(),
'Q22': eda["Q22"].tolist(),
'Q23': eda["Q23"].tolist(),
'Q24': eda["Q24"].tolist(),
'Q25': eda["Q25"].tolist(),
'Q26': eda["Q26"].tolist(),
'Q27': eda["Q27"].tolist(),
'Q28': eda["Q28"].tolist(),
'Q29': eda["Q29"].tolist(),
'Q30': eda["Q30"].tolist(),
'Q31': eda["Q31"].tolist(),
'Q32': eda["Q32"].tolist(),
'Q33': eda["Q33"].tolist(),
'Q34': eda["Q34"].tolist(),
'Q35': eda["Q35"].tolist(),
'Q36': eda["Q36"].tolist(),
'Q37': eda["Q37"].tolist(),
'Q38': eda["Q38"].tolist(),
'Q39': eda["Q39"].tolist(),
'Q40': eda["Q40"].tolist(),
'Q41': eda["Q41"].tolist(),
'Q42': eda["Q42"].tolist(),
'Q43': eda["Q43"].tolist(),
'Q44': eda["Q44"].tolist(),
'Q45': eda["Q45"].tolist(),
'Q46': eda["Q46"].tolist(),
'Q47': eda["Q47"].tolist(),
'Q48': eda["Q48"].tolist(),
'Q49': eda["Q49"].tolist(),
'Q50': eda["Q50"].tolist(),
'Q51': eda["Q51"].tolist(),
'Q52': eda["Q52"].tolist(),
'Q53': eda["Q53"].tolist(),
'Q54': eda["Q54"].tolist()
})
# ------- PART 1: Create background
# number of variable
categories=list(df)[1:]
N = len(categories)
# What will be the angle of each axis in the plot? (we divide the plot / number of variable)
angles = [n / float(N) * 2 * pi for n in range(N)]
angles += angles[:1]
# Initialise the spider plot
ax = plt.subplot(111, polar=True)
# If you want the first axis to be on top:
ax.set_theta_offset(pi / 2)
ax.set_theta_direction(-1)
# Draw one axe per variable + add labels
plt.xticks(angles[:-1], categories)
# Draw ylabels
ax.set_rlabel_position(0)
plt.yticks([0,2,4], ["0","2","4"], color="grey", size=7)
plt.ylim(0,4)
# ------- PART 2: Add plots
# Ind1
values=df.loc[0].drop('group').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="Divorce0")
ax.fill(angles, values, 'b', alpha=0.1)
# Ind2
values=df.loc[1].drop('group').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="Divorce1")
ax.fill(angles, values, 'r', alpha=0.1)
# Add legend
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
plt.gcf().set_size_inches(15, 15)
# Show the graph
plt.show()