

動機
飼い主の入力したテキストから、病気の可能性をあぶり出すというAI・機械学習があったらいいなと思います。
以前、既存の学習モデル(Zero-Shot Classification)を用いて、新たに学習させることなく、飼い主の相談内容から病気のジャンル分けを試みました。
今度は、自分の持っているデータを用いて、モデルを学習させます。そしてテキスト内容を分類したいと思います。
学習させるデータは、飼い主が獣医師に対して相談する想定でrinnaを用いてテキスト作成させました。AIを用いて学習データを作成させ、他のAIでそれを使って学習するという流れです。
rinnaに作成させたデータは、以下の文章から始まる文章を作成させたものです。それぞれ100文(計200)作成させた場合と、それぞれ1000文(計2000)作成させた場合を試してみました。
”犬が緊急事態” → ラベル1
“犬がリラックスしている。” → ラベル0
この学習させたモデルを使って、飼い主の相談内容から動物の緊急状態を推定するモデルを作ります。
目標は、以下のような相談を、緊急か非緊急かを自動で判断させることです。
「嘔吐、意識薄れている」→ 緊急
「徐々に、痩せてきた」→ 非緊急
「尿が一回もでない」→ 緊急
コード
NLPには、simpletransformersというパッケージを使用します。transformersを使いやすくしてくれるものです。google colabを想定しています。できたらGPUを使いたいところ。
まずは、学習させるためのデータを用意します。rinnaで作成したデータを読み込みます。データフレームは、コラム0にテキスト、コラム1にラベルとなるようにする。また、列名をtext、labelsにする。
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_excel("created_sentences.xlsx")
# ラベルが均等に分かれるようにstratifyで工夫。
train_x, test_x, train_y, test_y = train_test_split(df["sentence"],df["label"],test_size=0.2, stratify=df["label"])
# xとyに分かれるから、それをくっつけて1つのデータフレームにする
train_df = pd.concat([train_x.to_frame(),train_y.to_frame()],axis=1)
test_df = pd.concat([test_x.to_frame(),test_y.to_frame()],axis=1)
# ラベルをintegerにしておく
train_df["label"] = train_df["label"].astype("int")
test_df["label"] = test_df["label"].astype("int")
# データフレームの名前は決められているから、修正
test_df.columns=["text","labels"]
train_df.columns=["text","labels"]ラベルを変えておかないと、学習させる際に以下のエラーが起きます。
# 602: UserWarning: Dataframe headers not specified. Falling back to using column 0 as text and column 1 as labels.# “Dataframe headers not specified. Falling back to using column 0 as text and column 1 as labels.”
どんなデータになったのか、見てみます。
train_df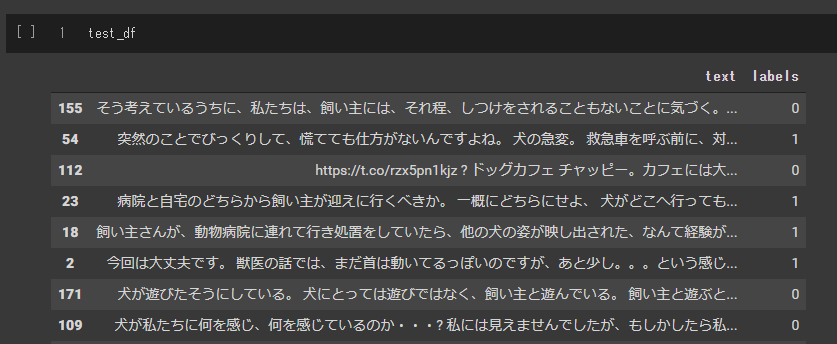
simpletransformersとtransformersをインストールします。
!pip install -q transformers
!pip install -q simpletransformers
このタイミングでランタイムを再起動しておいてください。
さっそく学習済みモデルを読み込んで、学習させずにテストデータを分類させてみます。そして、結果を評価したいと思います。
ここで使用させていただいている学習済みモデルは、東北大学(Inui Laboratory)が公開しているBERT base Japanese (IPA dictionary, whole word masking enabled)というモデルです。
https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking
The pretrained models are distributed under the terms of the Creative Commons Attribution-ShareAlike 3.0.
num_labelsは、目的の分類クラスの種類です。cuda使う場合は、use_cudaはTrueにしてください。使ったほうが圧倒的に早いです。
from simpletransformers.classification import ClassificationModel
# 学習モデルの読み込み
model = ClassificationModel("bert",
"cl-tohoku/bert-base-japanese-whole-word-masking",
num_labels=2,
use_cuda=False)
# モデルの性能を評価する
result, model_outputs, wrong_predictions = model.eval_model(test_df)
print(result){'mcc': 0.140028008402801, 'tp': 4, 'tn': 18, 'fp': 2, 'fn': 16, 'auroc': 0.5675, 'auprc': 0.5909497527901446, 'eval_loss': 0.6922034859657288}
resultは、confusion matrixのスコアを返してきます。あんまり見たことないスコアが多いですが、true positive negative false postive negativeを見れば、このモデルは全く判別できていないことがわかります。ほぼ全部ネガティブで押し切ろうとしています。学習していないのですから、そうなります。
自分でも、confusion matrixのスコアを計算してみます。model_outputsには、確率がでてきます。
import numpy as np
from sklearn.metrics import classification_report
temp = [np.argmax(item) for item in model_outputs]
print(classification_report(test_y,temp)) 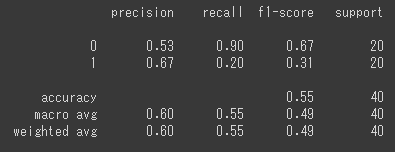
accuracyが0.55なのは、全く判別できていないということです。
さて、今度は学習させてから評価したいと思います。
from simpletransformers.classification import ClassificationModel
# 学習モデルの読み込み
model = ClassificationModel('bert',
'cl-tohoku/bert-base-japanese-whole-word-masking',
num_labels=2,
use_cuda=False)
# 学習させる
model.train_model(train_df)
# モデルを評価する
result, model_outputs, wrong_predictions = model.eval_model(test_df)
print(result){‘mcc’: 0.4605661864718383, ‘tp’: 7, ‘tn’: 20, ‘fp’: 0, ‘fn’: 13, ‘auroc’: 0.84, ‘auprc’: 0.8835313937423741, ‘eval_loss’: 0.61125648021698}
以下のようなエラーがでたら、このセルの先頭に以下のコマンドをつけて、outputsフォルダ内を消去してください。
!rm -rf outputs/
# ValueError: Output directory (outputs/) already exists and is not empty. Set overwrite_output_dir: True to automatically overwrite.
さいど、自分でスコアを計算してみます。
import numpy as np
from sklearn.metrics import classification_report
temp = [np.argmax(item) for item in model_outputs]
print(classification_report(test_y,temp)) 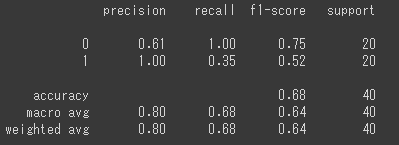
accuracyが0.68になりました。学習はしたけどかなり弱めです。それではこのモデルの実力を見てみます。
嘔吐してぐったりしている。呼吸も早い。 をどう判断するでしょうか。
label_list = ["緊急事態","急がなくてよい"]
predictions, raw_outputs = model.predict(["嘔吐してぐったりしている。呼吸も早い。"])
print(label_list[predictions[0]])緊急事態
よしいいぞ!
犬がゆっくりしている。
緊急事態
ええ~。これは、ダメですね。データ数を2000個に増やして再学習させます。
再度、学習させないで評価させてみます。
from simpletransformers.classification import ClassificationModel
model = ClassificationModel("bert","cl-tohoku/bert-base-japanese-whole-word-masking", num_labels=2, use_cuda=False)
result, model_outputs, wrong_predictions = model.eval_model(test_df)
print(result){‘mcc’: 0.0, ‘tp’: 0, ‘tn’: 100, ‘fp’: 0, ‘fn’: 100, ‘auroc’: 0.5779000000000001, ‘auprc’: 0.5920966829123682, ‘eval_loss’: 0.712486572265625}
import numpy as np
from sklearn.metrics import classification_report
temp = [np.argmax(item) for item in model_outputs]
print(classification_report(test_y,temp)) 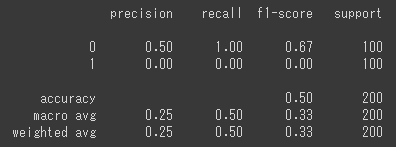
from simpletransformers.classification import ClassificationModel
model = ClassificationModel('bert', 'cl-tohoku/bert-base-japanese-whole-word-masking',num_labels=2, use_cuda=False)
model.train_model(train_df)
result, model_outputs, wrong_predictions = model.eval_model(test_df)
print(result){‘mcc’: 0.72, ‘tp’: 86, ‘tn’: 86, ‘fp’: 14, ‘fn’: 14, ‘auroc’: 0.947, ‘auprc’: 0.9512605841666181, ‘eval_loss’: 0.3560256278514862}
import numpy as np
from sklearn.metrics import classification_report
temp = [np.argmax(item) for item in model_outputs]
print(classification_report(test_y,temp)) 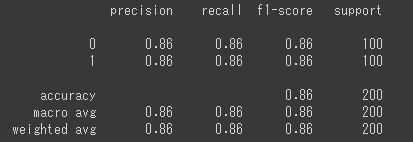
だいぶ良くなりました。
嘔吐してぐったりしている。呼吸も早い。
この言葉を再度評価させます。
label_list = ["緊急事態","急がなくてよい"]
predictions, raw_outputs = model.predict(["嘔吐してぐったりしている。呼吸も早い。"])
print(label_list[predictions[0]])緊急事態
犬がだんだん痩せてきた。
緊急事態。→ うーん。そうかな。
犬が最近、食欲がなくなってきた
急がなくてよい。→ 緊急ではないでしょう。
さっきよりは、だいぶ良くなっている気がします。accuracy 0.86だからまだ改善の余地ありって感じですね。ただ、緊急か緊急じゃないかは見逃したら大変なのでaccuracyではなく、sensitivityの向上を目指した方がいいですね。sensitivityも86%なので、もっと改善すべきですね。
学習時の設定事項について
このページに、学習時に設定できる事項が書いてありました。early stoppingとかbestモデルの保存場所とか決められるということがわかりました。
https://simpletransformers.ai/docs/usage/
以下のように使えます。
from simpletransformers.classification import ClassificationModel
# パラメータの設定
model_args = {
"num_train_epochs": 5,
"evaluate_during_training":True,
"best_model_dir":"/content/bestmodel",
"output_dir":"/content/output_dir4",
"use_early_stopping":True
}
# モデルの読み込み
model3 = ClassificationModel('bert',
'cl-tohoku/bert-base-japanese-whole-word-masking',
num_labels=2,
use_cuda=False,
args=model_args)
train_df2, eval_df = train_test_split(train_df,test_size=0.1)
model3.train_model(train_df2, eval_df= eval_df)
result, model_outputs, wrong_predictions = model3.eval_model(test_df)
print(result)ちなみに保存されたモデルを呼び出すときは、以下のように書きます。
model4 = ClassificationModel(
"bert",
"/content/bestmodel", # 学習時bestmodelに指定したフォルダ
use_cuda=False
)読み込んだモデルを使って、予測するには今までと同じ方法です。
predictions, raw_outputs = model4.predict(["犬が最近、食欲がなくなってきた。"])
print(predictions)
print(raw_outputs)
print(label_list[predictions[0]])Google colabでフォルダごと保存するときは、以下のようにします。
# zip -r 新しくできるzipの名前 保存したいフォルダのパス
!zip -r /content/download.zip /content/output_dir出来上がったらZIPファイルを右クリックしてダウンロードできます。7GBあったので、びっくりしました。