
NLP
Natural Language Processing(NLP)の分野の発展は目覚ましいものがあります。ただ、それに伴い凄まじい勢いでスタンダードが変わっていくので勉強するのが大変です。1年前はギリギリ、2年前の情報は使い物にならないような状況なので、最新の情報を探すだけでもヘトヘトになりました。現在時点(2021年6月)では、既にBERTが様々なモデルに抜かれながらも、縮小版のALBERTとともに、先頭集団で頑張っているというところでしょうか。
NLPの中でも感情分析(sentiment analysis)をまずやってみたいと思っていました。大量の文章があった場合に、その文書がポジティブなのか、ネガティブなのかを分類してくれます。自社の反応なんかもみれると思います。機械学習のclassificationタスクですが、自然言語処理タスクになるととても難しい。。でも、transformersというパッケージを使えばそれなりに簡単にできることがわかりました。
Transformers
最初つまづいたのですが、transformersはCNNとか、LSTMとかの種類としてのtransformerを提供するのではなく、色々なモデルを提供しているAPI的なやつです。これを使って、感情分析タスクを実行したいと思います。自分で学習させるほどデータをもっていないので、学習済みモデルを使用させてもらいます。
以下の記事を参考にさせていただきました。
https://note.com/npaka/n/ne0adde2d7ae8
さっそくコード実行
!pip install -q transformers[ja]
from transformers import AutoModelForSequenceClassification, BertJapaneseTokenizer,pipeline
# 学習済みモデルの読込み
model = AutoModelForSequenceClassification.from_pretrained('daigo/bert-base-japanese-sentiment')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)さっそく試してみたいと思います。google colabで上のコードを実行します。
さて、この文章はどうでしょうか。わりと簡単なやつです。
print(nlp("今日の獣医は信頼できる獣医だった。とても誠実だった。"))
print(nlp("最悪な獣医だった。二度と行きたくない。"))[{‘label’: ‘ポジティブ’, ‘score’: 0.9755786657333374}]
[{‘label’: ‘ネガティブ’, ‘score’: 0.9778217077255249}]
まあ当然でしょう。
今度は、行為についてうまいかどうかでポジティブとネガティブを分別したいと思います。
print(nlp("今日の獣医は、採血が上手だった"))
print(nlp("今日の獣医は、採血を何回も失敗していた。"))[{‘label’: ‘ポジティブ’, ‘score’: 0.97597336769104}]
[{‘label’: ‘ネガティブ’, ‘score’: 0.915653645992279}]
採血を何回も失敗したらネガティブとされるのは仕方ありません。でも、ネガティブ確率、91%と高くだすのやめてもらってもいいですか?血管逃げるやつは難しいよ😢
これは激ムズ問題です。
print(nlp("今日の獣医は優しい先生だった。\
でも、今後の治療について選択肢を与えるだけで、\
獣医師としてどの治療を選択すべきだと考えるかのアドバイスがなかった"))
print(nlp("今日の動物病院は、\
設備がしっかりしていて安心だが、\
料金がたかい"))[{‘label’: ‘ネガティブ’, ‘score’: 0.6615576148033142}]
[{‘label’: ‘ポジティブ’, ‘score’: 0.5392961502075195}]
ほうほう勉強になります。どちらとも、確率は高くなく断定できるレベルではなさそうですね。
獣医師・動物病院に対する感情分析
以前(2021年1月)、ツイッターのAPIを使って検索ワード獣医、動物病院をそれぞれ検索してツイートを入手しました。既に入手しているツイートデータを使って、感情分析を行いたいと思います。
CSVファイルには、ツイートの内容が1行づつ入っています。1行ずつ判断していきます。それを新しい列に入れていきます。
import pandas as pd
df = pd.read_excel("/content/tweet_動物病院.xlsx")
df['sentiment'] = 0
for i,item in enumerate(df.iloc[:,2]):
print(df.iloc[i,2])
result = nlp(df.iloc[i,2])[0]["label"]
print(result)
df.iloc[i,4] = nlp(df.iloc[i,2])[0]["label"]
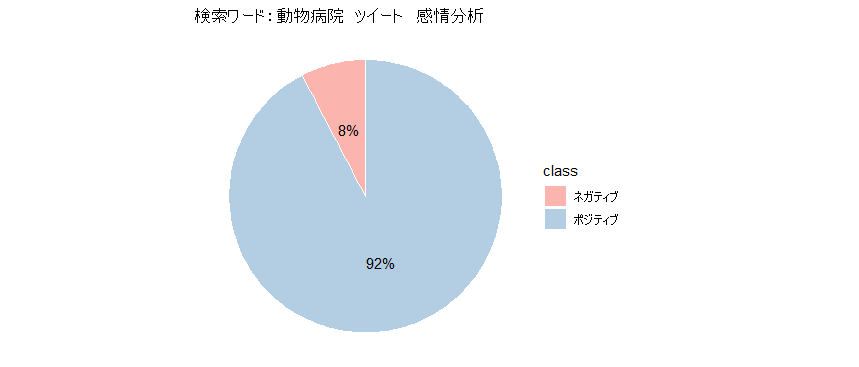
df.to_csv("sentiment_doubutubyoin.csv")動物病院で検索した場合の結果。
tweet数:6752
検索キーワード:動物病院
期間:2021年1月18日~2021年1月26日
tweet数:5803
検索キーワード:獣医
期間:2021年1月18日~2021年1月26日
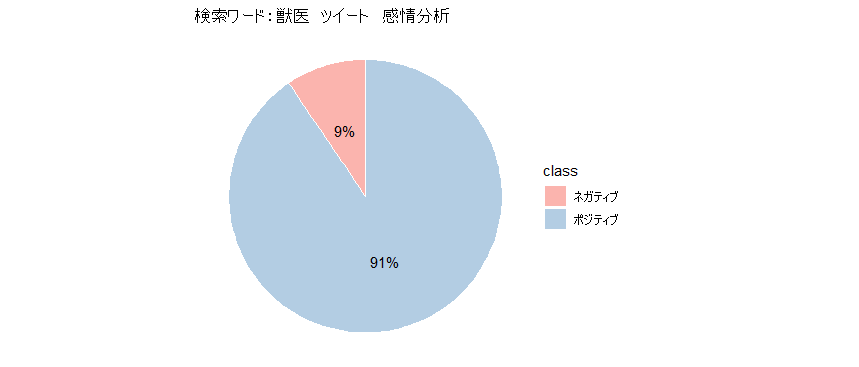
おおむね、ポジティブなツイートが多かったです!うれしいですね。