
Brute force feature engineeringとはなにか
Brute force feature engineeringとは、機械学習において特徴量に様々な処理を加えることで新しい特徴量を作り出して、とにかく精度を上げる手法です。feature engineeringは、通常ドメイン知識を生かして特徴量から意味のある手法で新たな特徴量を生み出すことが多いです。例えば、日にちの列から、休日を取り出して新たな特徴量とする等。
Brute force feature engineeringの手法では、可能な限りの特徴の組み合わせを作成し、どの特徴がモデルのパフォーマンスを向上させるかを検証します。この方法は計算量が多く、時間に時間かかります。
sklearnには、特徴量を作成する際の関数をtransformerと呼びますが、このtransformerを一発で取得できる関数があります。それはall_estimatorsというものです。
sklearn all_estimatorsで取得できるtransformerについて
all_estimatorsの引数type_filterにtransformerを渡します
注:all_estimatorsは1.2.2では以下のように場所が変更されています
from sklearn.utils.discovery import all_estimators
from sklearn.utils import all_estimators
# scikit-learn 1.2.2では from sklearn.utils.discovery import all_estimators
all_estimators(type_filter="transformer")[(‘AdditiveChi2Sampler’, sklearn.kernel_approximation.AdditiveChi2Sampler),
(‘BernoulliRBM’, sklearn.neural_network._rbm.BernoulliRBM),
(‘Binarizer’, sklearn.preprocessing._data.Binarizer),
(‘Birch’, sklearn.cluster._birch.Birch),
(‘BisectingKMeans’, sklearn.cluster._bisect_k_means.BisectingKMeans),
(‘CCA’, sklearn.cross_decomposition._pls.CCA),
(‘ColumnTransformer’, sklearn.compose._column_transformer.ColumnTransformer),
(‘DictVectorizer’,
sklearn.feature_extraction._dict_vectorizer.DictVectorizer),
(‘DictionaryLearning’,
sklearn.decomposition._dict_learning.DictionaryLearning),
(‘FactorAnalysis’, sklearn.decomposition._factor_analysis.FactorAnalysis),
(‘FastICA’, sklearn.decomposition._fastica.FastICA),
(‘FeatureAgglomeration’, sklearn.cluster._agglomerative.FeatureAgglomeration),
(‘FeatureHasher’, sklearn.feature_extraction._hash.FeatureHasher),
(‘FeatureUnion’, sklearn.pipeline.FeatureUnion),
(‘FunctionTransformer’,
sklearn.preprocessing._function_transformer.FunctionTransformer),
(‘GaussianRandomProjection’,
sklearn.random_projection.GaussianRandomProjection),
(‘GenericUnivariateSelect’,
sklearn.feature_selection._univariate_selection.GenericUnivariateSelect),
(‘HashingVectorizer’, sklearn.feature_extraction.text.HashingVectorizer),
(‘IncrementalPCA’, sklearn.decomposition._incremental_pca.IncrementalPCA),
(‘Isomap’, sklearn.manifold._isomap.Isomap),
(‘IsotonicRegression’, sklearn.isotonic.IsotonicRegression),
(‘IterativeImputer’, sklearn.impute._iterative.IterativeImputer),
(‘KBinsDiscretizer’, sklearn.preprocessing._discretization.KBinsDiscretizer),
(‘KMeans’, sklearn.cluster._kmeans.KMeans),
(‘KNNImputer’, sklearn.impute._knn.KNNImputer),
(‘KNeighborsTransformer’, sklearn.neighbors._graph.KNeighborsTransformer),
(‘KernelCenterer’, sklearn.preprocessing._data.KernelCenterer),
(‘KernelPCA’, sklearn.decomposition._kernel_pca.KernelPCA),
(‘LabelBinarizer’, sklearn.preprocessing._label.LabelBinarizer),
(‘LabelEncoder’, sklearn.preprocessing._label.LabelEncoder),
(‘LatentDirichletAllocation’,
sklearn.decomposition._lda.LatentDirichletAllocation),
(‘LinearDiscriminantAnalysis’,
sklearn.discriminant_analysis.LinearDiscriminantAnalysis),
(‘LocallyLinearEmbedding’,
sklearn.manifold._locally_linear.LocallyLinearEmbedding),
(‘MaxAbsScaler’, sklearn.preprocessing._data.MaxAbsScaler),
(‘MinMaxScaler’, sklearn.preprocessing._data.MinMaxScaler),
(‘MiniBatchDictionaryLearning’,
sklearn.decomposition._dict_learning.MiniBatchDictionaryLearning),
(‘MiniBatchKMeans’, sklearn.cluster._kmeans.MiniBatchKMeans),
(‘MiniBatchNMF’, sklearn.decomposition._nmf.MiniBatchNMF),
(‘MiniBatchSparsePCA’, sklearn.decomposition._sparse_pca.MiniBatchSparsePCA),
(‘MissingIndicator’, sklearn.impute._base.MissingIndicator),
(‘MultiLabelBinarizer’, sklearn.preprocessing._label.MultiLabelBinarizer),
(‘NMF’, sklearn.decomposition._nmf.NMF),
(‘NeighborhoodComponentsAnalysis’,
sklearn.neighbors._nca.NeighborhoodComponentsAnalysis),
(‘Normalizer’, sklearn.preprocessing._data.Normalizer),
(‘Nystroem’, sklearn.kernel_approximation.Nystroem),
(‘OneHotEncoder’, sklearn.preprocessing._encoders.OneHotEncoder),
(‘OrdinalEncoder’, sklearn.preprocessing._encoders.OrdinalEncoder),
(‘PCA’, sklearn.decomposition._pca.PCA),
(‘PLSCanonical’, sklearn.cross_decomposition._pls.PLSCanonical),
(‘PLSRegression’, sklearn.cross_decomposition._pls.PLSRegression),
(‘PLSSVD’, sklearn.cross_decomposition._pls.PLSSVD),
(‘PolynomialCountSketch’, sklearn.kernel_approximation.PolynomialCountSketch),
(‘PolynomialFeatures’, sklearn.preprocessing._polynomial.PolynomialFeatures),
(‘PowerTransformer’, sklearn.preprocessing._data.PowerTransformer),
(‘QuantileTransformer’, sklearn.preprocessing._data.QuantileTransformer),
(‘RBFSampler’, sklearn.kernel_approximation.RBFSampler),
(‘RFE’, sklearn.feature_selection._rfe.RFE),
(‘RFECV’, sklearn.feature_selection._rfe.RFECV),
(‘RadiusNeighborsTransformer’,
sklearn.neighbors._graph.RadiusNeighborsTransformer),
(‘RandomTreesEmbedding’, sklearn.ensemble._forest.RandomTreesEmbedding),
(‘RobustScaler’, sklearn.preprocessing._data.RobustScaler),
(‘SelectFdr’, sklearn.feature_selection._univariate_selection.SelectFdr),
(‘SelectFpr’, sklearn.feature_selection._univariate_selection.SelectFpr),
(‘SelectFromModel’, sklearn.feature_selection._from_model.SelectFromModel),
(‘SelectFwe’, sklearn.feature_selection._univariate_selection.SelectFwe),
(‘SelectKBest’, sklearn.feature_selection._univariate_selection.SelectKBest),
(‘SelectPercentile’,
sklearn.feature_selection._univariate_selection.SelectPercentile),
(‘SequentialFeatureSelector’,
sklearn.feature_selection._sequential.SequentialFeatureSelector),
(‘SimpleImputer’, sklearn.impute._base.SimpleImputer),
(‘SkewedChi2Sampler’, sklearn.kernel_approximation.SkewedChi2Sampler),
(‘SparseCoder’, sklearn.decomposition._dict_learning.SparseCoder),
(‘SparsePCA’, sklearn.decomposition._sparse_pca.SparsePCA),
(‘SparseRandomProjection’, sklearn.random_projection.SparseRandomProjection),
(‘SplineTransformer’, sklearn.preprocessing._polynomial.SplineTransformer),
(‘StackingClassifier’, sklearn.ensemble._stacking.StackingClassifier),
(‘StackingRegressor’, sklearn.ensemble._stacking.StackingRegressor),
(‘StandardScaler’, sklearn.preprocessing._data.StandardScaler),
(‘TfidfTransformer’, sklearn.feature_extraction.text.TfidfTransformer),
(‘TruncatedSVD’, sklearn.decomposition._truncated_svd.TruncatedSVD),
(‘VarianceThreshold’,
sklearn.feature_selection._variance_threshold.VarianceThreshold),
(‘VotingClassifier’, sklearn.ensemble._voting.VotingClassifier),
(‘VotingRegressor’, sklearn.ensemble._voting.VotingRegressor)]
すべての関数をデータにかけるには、make_unionを使います。sklearnには、関数をデータに対して直列(make_pipeline)にかけていく関数と、平行にかけていく関数(make_union)の2つがあります。今回はすべての関数を平行にかけたいと考えました。
データに対して使用できるtransformerのリストを取得する自作関数
def get_usable_transformer(x):
"""
get all transformers that can be applied to the data
Args:
x (_type_): independent variable
Returns:
transformers_list: list of usable transformers
"""
from sklearn.utils import all_estimators
from scipy.sparse._csr import csr_matrix
from sklearn.pipeline import make_union
from sklearn.model_selection import train_test_split
transfomers_list = list()
x_train,x_test= train_test_split(x)
for transformer in all_estimators(type_filter="transformer"):
try:
print(transformer[1]())
this_union = make_union(transformer[1](),verbose=0)
this_union.fit(x_train)
fitted = this_union.transform(x_train)
this_union.transform(x_test)
if type(fitted) != type(csr_matrix(arg1=1)):
transfomers_list.append(transformer[1]())
else:
print("skipped because this model yields csr matrix")
continue
except:
print("error")
continue
return transfomers_list使い方
データとして、sklearnに入っている糖尿病のデータを使ってみます。このデータにフィットするtransformerを自作関数を使って取得します。
from sklearn.datasets import load_diabetes
x,y = load_diabetes(return_X_y=True)
transformers = get_usable_transformer(x)
transformers[BernoulliRBM(),
Binarizer(),
Birch(),
BisectingKMeans(),
DictionaryLearning(),
FactorAnalysis(),
FastICA(),
FeatureAgglomeration(),
FunctionTransformer(),
IncrementalPCA(),
Isomap(),
IterativeImputer(),
KMeans(),
KNNImputer(),
KernelPCA(),
LocallyLinearEmbedding(),
MaxAbsScaler(),
MinMaxScaler(),
MiniBatchDictionaryLearning(),
MiniBatchKMeans(),
MiniBatchSparsePCA(),
MissingIndicator(),
Normalizer(),
Nystroem(),
PCA(),
PolynomialCountSketch(),
PolynomialFeatures(),
PowerTransformer(),
QuantileTransformer(),
RBFSampler(),
RobustScaler(),
SimpleImputer(),
SkewedChi2Sampler(),
SparsePCA(),
SplineTransformer(),
StandardScaler(),
TruncatedSVD(),
VarianceThreshold()]
では、実際に学習するところまで書いてみます。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y)
from sklearn.pipeline import make_union
brute_force_features_engineering = make_union(*transformers,verbose=True)
brute_force_features_engineering
すべて元データに対して平行にかけています。これにHistGradientBoostingRegressorを直列に追加します。
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(brute_force_features_engineering,HistGradientBoostingRegressor())
pipe
スコアをmean_absolute_errorとしてcrossvalidation5回でかけてみます。
from sklearn.model_selection import cross_val_score
cross_val_score(pipe,X=x,y=y,cv=5,scoring='neg_mean_absolute_error')*-1array([43.17031658, 44.22102714, 47.52285663, 44.94645319, 47.83686965])
では、brute_force_features_engineeringなしでHistGradientBoostingRegressorだけではどうだったのでしょうか。
cross_val_score(HistGradientBoostingRegressor(),
x,y,cv=5,scoring='neg_mean_absolute_error')*-1array([43.53088138, 46.00439038, 50.35688135, 47.34385822, 47.90363144])
評価
箱ひげ図を書いてみます。
import plotly.express as px
import pandas as pd
fig = px.box(data_frame = pd.DataFrame({"BFE":[43.17031658, 44.22102714, 47.52285663, 44.94645319, 47.83686965],
"HGB":[43.53088138, 46.00439038, 50.35688135, 47.34385822, 47.90363144]}
)
)
fig.show()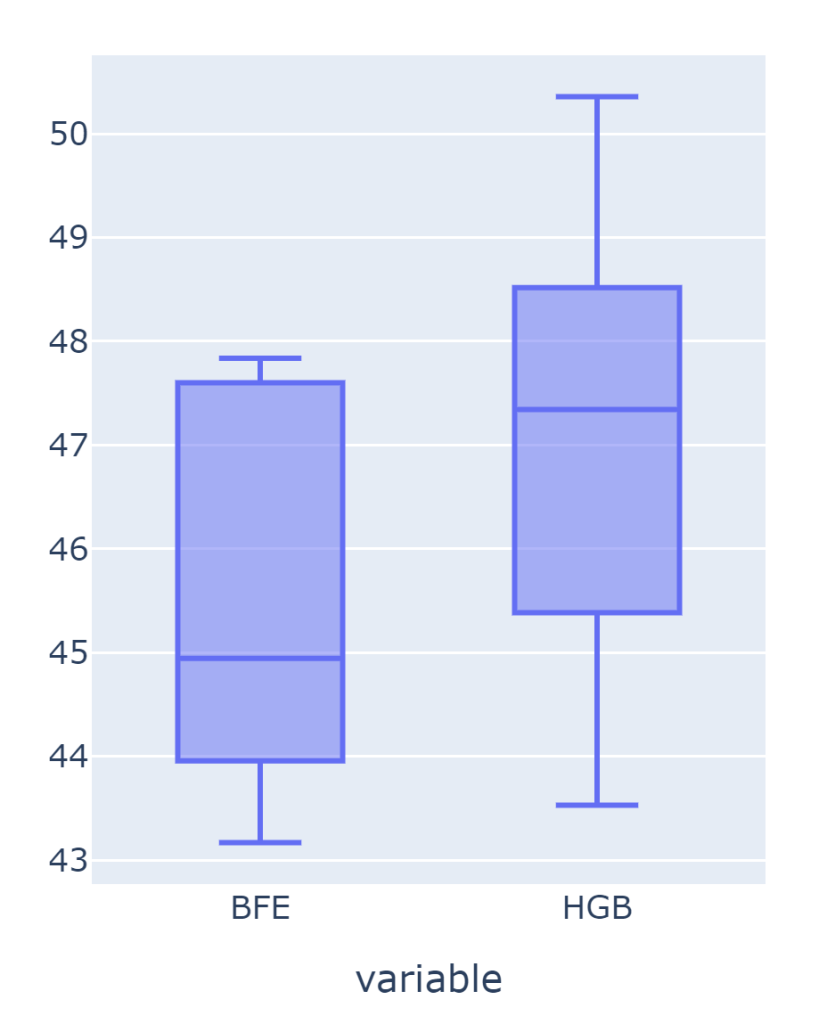
効果ありそうですね!T-testではどうでしょうか。
from scipy import stats
stats.ttest_ind([43.17031658, 44.22102714, 47.52285663, 44.94645319, 47.83686965],
[43.53088138, 46.00439038, 50.35688135, 47.34385822, 47.90363144],
equal_var=True)
Ttest_indResult(statistic=-1.0253991021766191, pvalue=0.3351779925430797)
平均値の差はなしとの結果になっていまいました。
ただ、可視化ではBrute force feature engineeringの方がよいスコアが出そうだったので、意味はあると思います!
ちなみにBrute force feature engineeringでどんな形のデータになっているのでしょうか。
x.shape
#(442, 10)
brute_force_features_engineering.fit_transform(x).shape
#(442, 1045)10個の列から1045個の列になっています。