sklearnのutilsにall_estimatorsという関数があります。これでtype_filterをするとclassifierを全部取得できることがわかりました。ちまちま普段使いのモデルを当てていかなくても自動で全部当ててくれます。
ちなみにauto-sklearnというautoMLライブラリがありますが、普通にはwindowsで動きません。ただ単にsklearnの中でいいやつを探したいライトユースのautoMLなら自分で書いてしまいましょう。
sklearn all_estimatorsで取得できるモデルについて
all_estimatorsの引数type_filterにclassifierを渡します
注:all_estimatorsは1.2.2では以下のように場所が変更されています
from sklearn.utils.discovery import all_estimators
from sklearn.utils import all_estimators
all_estimators(type_filter="classifier")[(‘AdaBoostClassifier’, sklearn.ensemble._weight_boosting.AdaBoostClassifier),
(‘BaggingClassifier’, sklearn.ensemble._bagging.BaggingClassifier),
(‘BernoulliNB’, sklearn.naive_bayes.BernoulliNB),
(‘CalibratedClassifierCV’, sklearn.calibration.CalibratedClassifierCV),
(‘CategoricalNB’, sklearn.naive_bayes.CategoricalNB),
(‘ClassifierChain’, sklearn.multioutput.ClassifierChain),
(‘ComplementNB’, sklearn.naive_bayes.ComplementNB),
(‘DecisionTreeClassifier’, sklearn.tree._classes.DecisionTreeClassifier),
(‘DummyClassifier’, sklearn.dummy.DummyClassifier),
(‘ExtraTreeClassifier’, sklearn.tree._classes.ExtraTreeClassifier),
(‘ExtraTreesClassifier’, sklearn.ensemble._forest.ExtraTreesClassifier),
(‘GaussianNB’, sklearn.naive_bayes.GaussianNB),
(‘GaussianProcessClassifier’,
sklearn.gaussian_process._gpc.GaussianProcessClassifier),
(‘GradientBoostingClassifier’,
sklearn.ensemble._gb.GradientBoostingClassifier),
(‘HistGradientBoostingClassifier’,
sklearn.ensemble._hist_gradient_boosting.gradient_boosting.HistGradientBoostingClassifier),
(‘KNeighborsClassifier’,
sklearn.neighbors._classification.KNeighborsClassifier),
(‘LabelPropagation’,
sklearn.semi_supervised._label_propagation.LabelPropagation),
(‘LabelSpreading’, sklearn.semi_supervised._label_propagation.LabelSpreading),
(‘LinearDiscriminantAnalysis’,
sklearn.discriminant_analysis.LinearDiscriminantAnalysis),
(‘LinearSVC’, sklearn.svm._classes.LinearSVC),
(‘LogisticRegression’, sklearn.linear_model._logistic.LogisticRegression),
(‘LogisticRegressionCV’, sklearn.linear_model._logistic.LogisticRegressionCV),
(‘MLPClassifier’,
sklearn.neural_network._multilayer_perceptron.MLPClassifier),
(‘MultiOutputClassifier’, sklearn.multioutput.MultiOutputClassifier),
(‘MultinomialNB’, sklearn.naive_bayes.MultinomialNB),
(‘NearestCentroid’, sklearn.neighbors._nearest_centroid.NearestCentroid),
(‘NuSVC’, sklearn.svm._classes.NuSVC),
(‘OneVsOneClassifier’, sklearn.multiclass.OneVsOneClassifier),
(‘OneVsRestClassifier’, sklearn.multiclass.OneVsRestClassifier),
(‘OutputCodeClassifier’, sklearn.multiclass.OutputCodeClassifier),
(‘PassiveAggressiveClassifier’,
sklearn.linear_model._passive_aggressive.PassiveAggressiveClassifier),
(‘Perceptron’, sklearn.linear_model._perceptron.Perceptron),
(‘QuadraticDiscriminantAnalysis’,
sklearn.discriminant_analysis.QuadraticDiscriminantAnalysis),
(‘RadiusNeighborsClassifier’,
sklearn.neighbors._classification.RadiusNeighborsClassifier),
(‘RandomForestClassifier’, sklearn.ensemble._forest.RandomForestClassifier),
(‘RidgeClassifier’, sklearn.linear_model._ridge.RidgeClassifier),
(‘RidgeClassifierCV’, sklearn.linear_model._ridge.RidgeClassifierCV),
(‘SGDClassifier’, sklearn.linear_model._stochastic_gradient.SGDClassifier),
(‘SVC’, sklearn.svm._classes.SVC),
(‘StackingClassifier’, sklearn.ensemble._stacking.StackingClassifier),
(‘VotingClassifier’, sklearn.ensemble._voting.VotingClassifier)]
全てのclassifierを試す自作関数
k-foldクロスバリデーション入りです。この関係で、cvは2以上にしないとエラーがでます。評価関数は、accuracyを使っていますが必要に応じて直してください。
def apply_all_classifier(x,y,cv=3):
"""
apply all classifiers in sklearn with k-fold cross validation
cv should be greater than or equal to 2
Args:
x (_type_): independent variable
y (_type_): target variable
cv (int, optional): how many folds. Defaults to 3.
"""
import time
from sklearn.utils import all_estimators
from sklearn.metrics import accuracy_score
results_df = pd.DataFrame(columns=["model_name","score","timeElapsed","cv"])
from sklearn.model_selection import KFold
kf = KFold(n_splits=cv,shuffle=True)
for i, (train_index, test_index) in enumerate(kf.split(X=x)):
x_train = x[train_index]
x_test = x[test_index]
y_train = y[train_index]
y_test = y[test_index]
for model in all_estimators(type_filter="classifier"):
results_df.to_csv("results.csv",index=False)
time_start = time.time()
try:
thismodel = model[1]()
print(model[0])
try:
thismodel.fit(x_train,y_train)
result = accuracy_score(y_true=y_test,
y_pred=thismodel.predict(x_test))
print(result)
time_spent = time.time()-time_start
results_df = pd.concat([results_df,
pd.DataFrame({"model_name":model[0],
"score":[result],
"timeElapsed":[time_spent],
"cv":[i]})],
axis=0)
except:
print("fitting error")
results_df = pd.concat([results_df,
pd.DataFrame({"model_name":model[0],
"score":["fittingError"],
"timeElapsed":[0],
"cv":[i]})],
axis=0)
except:
print("instanciating error")
results_df=pd.concat([results_df,
pd.DataFrame({"model_name":model[0],
"score":["instanciatingError"],
"timeElapsed":[0],
"cv":[i]})],
axis=0)
temp = results_df.pivot(index="model_name",columns="cv")
temp = temp.reset_index()
temp.columns = temp.columns.values
temp.columns = ["model_name"]+temp.columns[1:].to_list()
results_df["mean_score"] = pd.to_numeric(results_df["score"],errors="coerce")
results_df["mean_time"] = pd.to_numeric(results_df["timeElapsed"],errors="coerce")
results_df = (results_df.groupby("model_name"))[["mean_score","mean_time"]].agg("mean")
results_df = results_df.sort_values(by="mean_score",ascending=False)
results_df = results_df.reset_index()
results_df = results_df.merge(temp,on=["model_name"])
results_df.to_csv("results_classifier.csv",index=False)
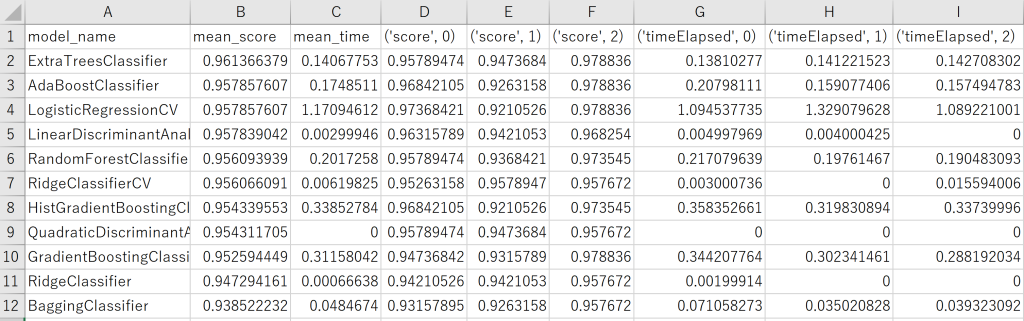
print("Done!")試しにsklearnの乳がんのデータセットを使ってみます。
使い方は、apply_all_classifier(説明変数、目的変数、kフォルドクロスバリデーションの回数)です。
import pandas as pd
from sklearn.datasets import load_breast_cancer
x,y = load_breast_cancer(return_X_y=True)
apply_all_classifier(x,y,cv=3)