
共起ネットワークとは、文章に出現する単語の共起関係(同時に出現する頻度や強さ)をネットワーク図で表現したものです。共起ネットワークを用いると、文章全体の語句の関連性や傾向を視覚的に把握することができます。
共起ネットワークでわかることは、例えば以下のようなことがあります。
– 文章の主要なテーマやキーワードを特定する
– 文章の中で頻繁に出現する単語やフレーズを抽出する
– 文章の中で密接に関連する単語やフレーズをグループ化する
– 文章の中で異なる意見や視点を持つ単語やフレーズを比較する
共起ネットワークを作成するためには、共起行列を得る必要があります。共起行列は以下のようなものです。
文1:単語Aは単語Bでした
文2:単語Aは単語Bではないか。
文3:単語Bでした。
文4:単語Bだった。
| 単語A | 単語B | |
| 単語A | 2 | 2 |
| 単語B | 2 | 4 |
この共起行列では以下のことがわかります。
単語Aと単語Bの欄は、2となっていますが2つの文で一緒に出てきたことがわかります。
単語Aと単語Aの欄は、2となっていますが2つの文で出てきたということです。
単語Bと単語Bの欄は、4となっていますが4つの文で出てきたということです。
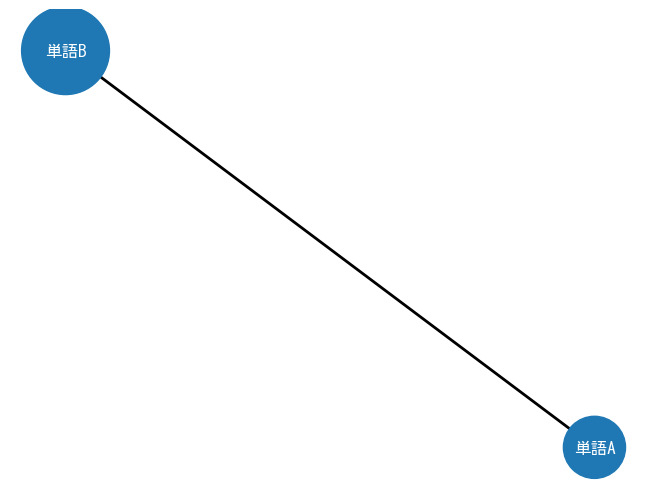
これを可視化します。丸の大きさは単語の出現頻度丸の間の線の大きさは2つの単語が1文中に一緒に出てくる頻度を示すようにnetworkxを使って可視化します。
import networkx as nx
G = nx.Graph()
G.add_edge("単語A","単語B",weight=2)
G.add_node("単語A",weight=2)
G.add_node("単語B",weight=4)
size_chousei = 1000
nx.draw(G,
font_family = "MS Gothic",
with_labels = True,
width=[2],#線の太さは単語Aと単語Bの共起数
node_size = [2*size_chousei,
4*size_chousei],#〇の大きさは単語AとBそれぞれの出現頻度
font_color="white"
)
非常に簡単な例を見てみましたが、実際の文章から共起行列を得るにはどうしたらいいでしょうか。
ステップ1:頻度行列を得る
ステップ2:頻度行列から共起行列を計算する
ステップ1:頻度行列を得る このステップのためには、sklearnのcountvectorizerという機能を使います。
sklearnのcountvectorizerの機能の説明より
テキストドキュメントのコレクションをトークン数の行列に変換します。特徴数はデータを解析して見つけた語彙のサイズと同じになります。
使い方を見てみます。英語が想定されている使い方なんだと思います。
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['this is English. That are this this.']
vectorizer = CountVectorizer()
x = vectorizer.fit_transform(corpus)
print("認識された単語:",vectorizer.get_feature_names_out())
print("カウント数:", x.todense())認識された単語: ['are' 'english' 'is' 'that' 'this'] カウント数: [[1 1 1 1 3]]
日本語でやってみます。
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['日本語の文章を解析するのは工夫が要ります']
vectorizer = CountVectorizer()
x = vectorizer.fit_transform(corpus)
print("認識された単語:",vectorizer.get_feature_names_out())
print("カウント数:", x.todense())認識された単語: ['日本語の文章を解析するのは工夫が要ります'] カウント数: [[1]]
すべてで1つの単語として認識されています。どうやらスペースが内からのようです。スペースをつけてもう一度やってみます。
corpus = ['日本語の文章を 解析するのは 工夫が要ります']
vectorizer = CountVectorizer()
x = vectorizer.fit_transform(corpus)
print("認識された単語:",vectorizer.get_feature_names_out())
print("カウント数:", x.todense())認識された単語: ['工夫が要ります' '日本語の文章を' '解析するのは'] カウント数: [[1 1 1]]
できましたが、すべての単語を手動でスペースを付けるのは限界があります。そこでspacyです。
import spacy
nlp = spacy.load("ja_ginza")
doc = nlp("日本語の分析を行います。単語の間にスペースを自動で入れたい")
alllist = list()
for sent in doc.sents:
thislist = list()
for token in sent:
thislist.append(token.lemma_)
print(" ".join(thislist))
alllist.append(" ".join(thislist))日本語 の 分析 を 行う ます 。 単語 の 間 に スペース を 自動 で 入れる たい
alllist['日本語 の 分析 を 行う ます 。', '単語 の 間 に スペース を 自動 で 入れる たい']
from sklearn.feature_extraction.text import CountVectorizer
corpus = alllist
vectorizer = CountVectorizer()
x = vectorizer.fit_transform(corpus)
print("認識された単語:",vectorizer.get_feature_names_out())
print("カウント数:")
print(x.todense())認識された単語: ['たい' 'ます' 'スペース' '入れる' '分析' '単語' '日本語' '自動' '行う'] カウント数: [[0 1 0 0 1 0 1 0 1] [1 0 1 1 0 1 0 1 0]]
なぜか1文字のものは削除されています。そのため、token_patternに正規表現を以下のように設定することで修正できます。
from sklearn.feature_extraction.text import CountVectorizer
corpus = alllist
vectorizer = CountVectorizer(token_pattern=r'(?u)\b\w+\b')
x = vectorizer.fit_transform(corpus)
print("認識された単語:",vectorizer.get_feature_names_out())
print("カウント数:")
print(x.todense())認識された単語: ['are' 'english' 'is' 'that' 'this'] カウント数: [[1 1 1 1 3]] 認識された単語: ['日本語の文章を解析するのは工夫が要ります'] カウント数: [[1]] 認識された単語: ['工夫が要ります' '日本語の文章を' '解析するのは'] カウント数: [[1 1 1]] 日本語 の 分析 を 行う ます 。 単語 の 間 に スペース を 自動 で 入れる たい ['日本語 の 分析 を 行う ます 。', '単語 の 間 に スペース を 自動 で 入れる たい'] 認識された単語: ['たい' 'ます' 'スペース' '入れる' '分析' '単語' '日本語' '自動' '行う'] カウント数: [[0 1 0 0 1 0 1 0 1] [1 0 1 1 0 1 0 1 0]] 認識された単語: ['たい' 'で' 'に' 'の' 'ます' 'を' 'スペース' '入れる' '分析' '単語' '日本語' '自動' '行う' '間'] カウント数: [[0 0 0 1 1 1 0 0 1 0 1 0 1 0] [1 1 1 1 0 1 1 1 0 1 0 1 0 1]]
(?u)はunicode(UTF-8)を示す
\bは単語の境界
\wはアルファベット、アンダーバー、数字
+は一回以上の繰り返し
ところで、「で」とか「に」とか不要なものがあります。というか、固有名詞(PROPN)、名詞(NOUN)、動詞(VERB)、形容詞(ADJ)だけでいいと思いました。
pos_をつけることで品詞がわかるのでした(wordcloudの記事を参照)
doc = nlp("日本語の分析を行います。単語の間にスペースを自動で入れたい。")
alllist = list()
for sent in doc.sents:
tokenlist = list()
for token in sent:
if token.pos_ in ["PROPN","NOUN","VERB","ADJ"]:
tokenlist.append(token.lemma_)
alllist.append(" ".join(tokenlist))
alllist['日本語 分析 行う', '単語 間 スペース 自動 入れる']
from sklearn.feature_extraction.text import CountVectorizer
corpus = alllist
vectorizer = CountVectorizer(token_pattern=r'(?u)\b\w+\b')
x = vectorizer.fit_transform(corpus)
print("認識された単語:",vectorizer.get_feature_names_out())
print("カウント数:")
print(x.todense())認識された単語: ['スペース' '入れる' '分析' '単語' '日本語' '自動' '行う' '間'] カウント数: [[0 0 1 0 1 0 1 0] [1 1 0 1 0 1 0 1]]
ステップ2:頻度行列から共起行列を計算する
頻度行列を得られたので、今度は共起行列を計算します。最初の簡単な例を考えてみます。
文1:単語Aは単語Bでした
文2:単語Aは単語Bではないか。
文3:単語Bでした。
文4:単語Bだった。
この共起行列を得るためには以下のような2つの行列計算で得られます。左側には頻度行列の転置、右側には頻度行列をおいて、行列の積を計算します。行列の積と聞くとうっとなりますが、意味するところは、単語Aと単語Bが同じ文にでてきたどうかを計算しているだけでです。
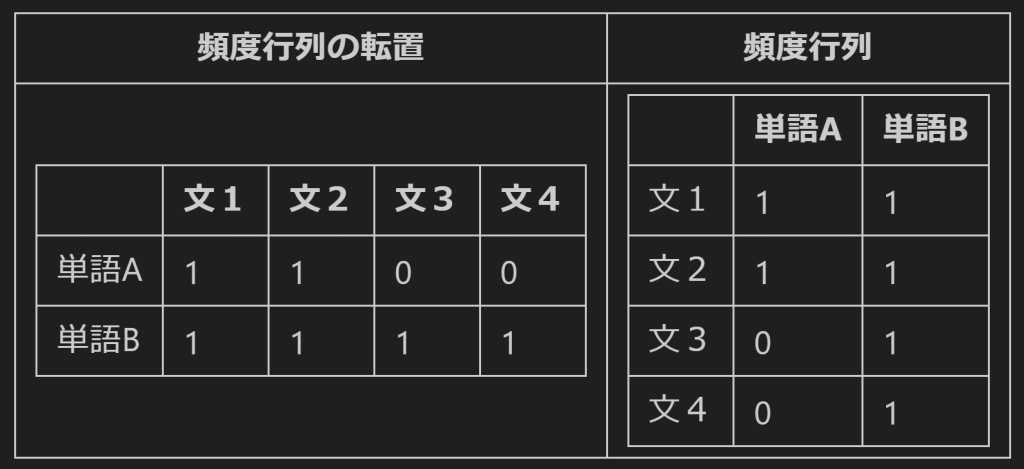
import pandas as pd
import numpy as np
tenchi = np.array([[1,1,0,0],
[1,1,1,1]])
hindo = np.array([[1,1],
[1,1],
[0,1],
[0,1]])
pd.DataFrame(np.dot(tenchi,hindo),
index=["単語A","単語B"],
columns=["単語A","単語B"])| 単語A | 単語B | |
| 単語A | 2 | 2 |
| 単語B | 2 | 4 |
ちなみに、転置行列は、.Tをつけるだけで簡単に得られます。
hindo.Tarray([[1, 1, 0, 0], [1, 1, 1, 1]])
左下の2(単語A列の単語B列)を得るためには、以下のような計算が行われています。
単語Bの文1:1×単語Aの文1:1+
単語Bの文2:1×単語Aの文2:1+
単語Bの文3:1×単語Aの文3:0+
単語Bの文4:1×単語Aの文4:0=2
ステップ1とステップ2を合わせて、実際の長い文章で共起行列を得るコードを書いてみます。
import spacy
nlp = spacy.load("ja_ginza")
doc = nlp("日本語の分析を行います。日本語の研究です")
alllist = list()
for sent in doc.sents:
tokenlist = list()
for token in sent:
if token.pos_ in ["PROPN","NOUN","VERB","ADJ"]:
tokenlist.append(token.lemma_)
alllist.append(" ".join(tokenlist))
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(token_pattern=r'(?u)\b\w+\b')
x = vectorizer.fit_transform(alllist)
import pandas as pd
pd.DataFrame(np.dot(x.T,x).todense(),
index=vectorizer.get_feature_names_out(),
columns = vectorizer.get_feature_names_out())| 分析 | 日本語 | 研究 | 行う | |
| 分析 | 1 | 1 | 0 | 1 |
| 日本語 | 1 | 2 | 1 | 1 |
| 研究 | 0 | 1 | 1 | 0 |
| 行う | 1 | 1 | 0 | 1 |
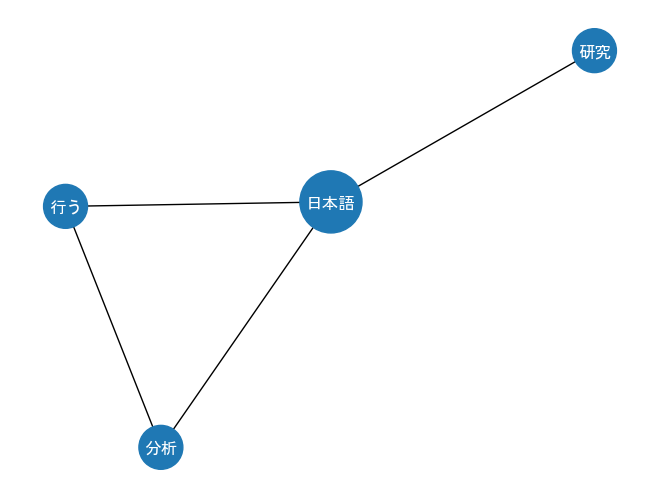
可視化します。
kyoki = pd.DataFrame(np.dot(x.T,x).todense(),
index=vectorizer.get_feature_names_out(),
columns = vectorizer.get_feature_names_out())
edge_list = list()
node_list = list()
num_word = len(kyoki)
for row in range(num_word):
for col in range(num_word):
if row<col:
if kyoki.iloc[row,col]!=0:
edge_list.append((kyoki.index[row],
kyoki.columns[col],
{"weight":kyoki.iloc[row,col]}
))
elif row == col:
node_list.append((kyoki.index[row],
{"weight":kyoki.iloc[row,col]}
))
print(edge_list)
print(node_list)[('分析', '日本語', {'weight': 1}), ('分析', '行う', {'weight': 1}), ('日本語', '研究', {'weight': 1}), ('日本語', '行う', {'weight': 1})] [('分析', {'weight': 1}), ('日本語', {'weight': 2}), ('研究', {'weight': 1}), ('行う', {'weight': 1})]
import networkx as nx
G = nx.Graph()
G.add_edges_from(edge_list)
G.add_nodes_from(node_list)
scalingfactor_edge = 1
scalingfactor_node = 1000
edge_weights = np.array(list(nx.get_edge_attributes(G,"weight").values()))
edge_weights = edge_weights*scalingfactor_edge
node_size = np.array(list(nx.get_node_attributes(G,"weight").values()))
node_size = node_size*scalingfactor_node
nx.draw(G,
font_family = "MS Gothic",
with_labels = True,
width= edge_weights,
node_size = node_size,
font_color="white"
)
pyvisを使うとインタラクティブなプロットを作成できます。数字のタイプをint64からintに変更する必要があるので微修正。
edge_list = list()
node_list = list()
num_word = len(kyoki)
for row in range(num_word):
for col in range(num_word):
if row<col:
if kyoki.iloc[row,col]!=0:
edge_list.append((kyoki.index[row],
kyoki.columns[col],
{"weight":int(kyoki.iloc[row,col])}
))
elif row == col:
node_list.append((kyoki.index[row],
{"weight":int(kyoki.iloc[row,col])}
))
import networkx as nx
G = nx.Graph()
G.add_edges_from(edge_list)
G.add_nodes_from(node_list)
scalingfactor_edge = 1
scalingfactor_node = 1000
edge_weights = np.array(list(nx.get_edge_attributes(G,"weight").values()))
edge_weights = edge_weights*scalingfactor_edge
node_size = np.array(list(nx.get_node_attributes(G,"weight").values()))
node_size = node_size*scalingfactor_node
nx.draw(G,
font_family = "MS Gothic",
with_labels = True,
width= edge_weights,
node_size = node_size,
font_color="white"
)
from pyvis.network import Network
nt = Network(width ='800px',
height='800px',
notebook=True)
for node,attrs in G.nodes(data=True):
nt.add_node(node,title=node,size=30*attrs["weight"],font_size=50)
for node1,node2,attrs in G.edges(data=True):
nt.add_edge(node1,node2,width=20*attrs["weight"])
nt.show_buttons()
nt.show("network.html")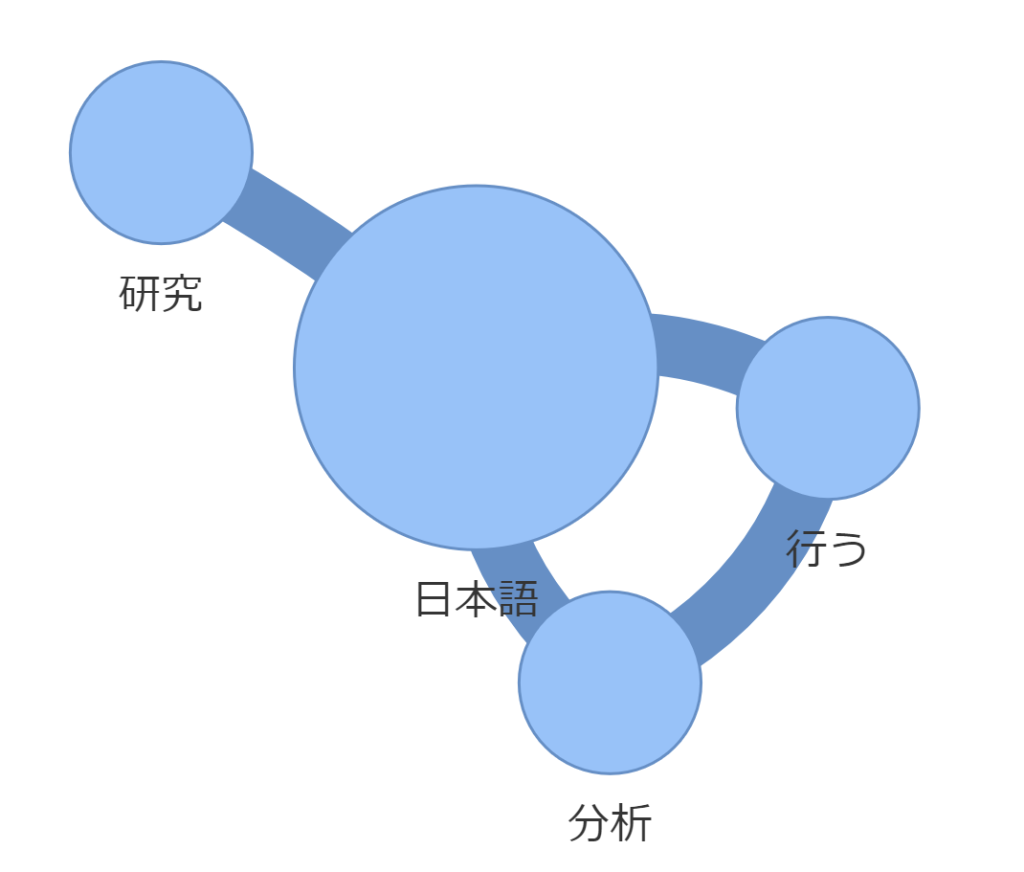
なぜかボタンは動きません。
議事録を使って共起ネットワークを作る
第211回国会 参議院 予算委員会 第17号 令和5年5月26日を使って、共起ネットワークを作ってみたいと思います。
https://kokkai.ndl.go.jp/#/detail?minId=121115261X01720230526¤t=37
text = """
第211回国会 参議院 予算委員会 第17号 令和5年5月26日
~~~省略~~~
"""このままspacyに読み込ませると、npl(text)のところでエラーがでます。
Exception: Tokenization error: Input is too long, it can’t be more than 49149 bytes, was 195779
長すぎるので、「。」をつかって分割します。
sentences = text.split("。")
sentences[57:60]['その一つの大きな原因は、やはり我が国における創薬基盤があって、そして、それぞれ治療で使う薬、診断薬や治療薬、ワクチン、これらに関して、いずれも我が国が世界でも先進的なそうした創薬の力を持っていたことが、こうした我が国が保健医療の分野で重要な役割を担うことができる比較優位性の一つの大事な基盤であったわけであります', '\n\u3000ところが、それが昨今揺らいできたということについての懸念がございます', '(資料提示)\n\u3000この世界の売上げ上位三百品目における日本の製薬企業創薬の製品数でありますけれども、減少し続けています']
import spacy
nlp = spacy.load("ja_ginza")
sentence_list = list()
for sentence in sentences:
doc = nlp(sentence)
tokenlist = list()
for sent in doc.sents:
for token in sent:
if token.pos_ in ["PROPN","NOUN","VERB","ADJ"]:
tokenlist.append(token.lemma_)
sentence_list.append(" ".join(tokenlist))
sentence_list[57:60]['つ 大きな 原因 国 おく 創薬 基盤 ある 治療 使う 薬 診断 薬 治療薬 ワクチン ら 関する 国 世界 先進的 する 創薬 力 持つ いる こと する 国 保健 医療 分野 重要 役割 担う こと 比較 優位性 つ 大事 基盤 ある わけ ある', '\n\u3000 ところ 揺らぐ くる いう こと つく 懸念 ござる', '資料 提示 \n\u3000 世界 売上げ 上位 三百 品目 おく 日本 製薬 企業 創薬 製品 数 ある 減少 続ける いる']
一気にコードを書くと以下のようになります。
import spacy
nlp = spacy.load("ja_ginza")
sentence_list = list()
for sentence in sentences:
doc = nlp(sentence)
tokenlist = list()
for sent in doc.sents:
for token in sent:
if token.pos_ in ["PROPN","NOUN","VERB","ADJ"]:
tokenlist.append(token.lemma_)
sentence_list.append(" ".join(tokenlist))
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(token_pattern=r'(?u)\b\w+\b')
x = vectorizer.fit_transform(sentence_list)
import pandas as pd
kyoki = pd.DataFrame(np.dot(x.T,x).todense(),
index=vectorizer.get_feature_names_out(),
columns = vectorizer.get_feature_names_out())
edge_list = list()
node_list = list()
num_word = len(kyoki)
for row in range(num_word):
for col in range(num_word):
if row<col:
if kyoki.iloc[row,col]!=0:
edge_list.append((kyoki.index[row],
kyoki.columns[col],
{"weight":int(kyoki.iloc[row,col])}
))
elif row == col:
node_list.append((kyoki.index[row],
{"weight":int(kyoki.iloc[row,col])}
))
import networkx as nx
G = nx.Graph()
G.add_edges_from(edge_list)
G.add_nodes_from(node_list)
scalingfactor_edge = 1
scalingfactor_node = 1
edge_weights = np.array(list(nx.get_edge_attributes(G,"weight").values()))
edge_weights = edge_weights*scalingfactor_edge
node_size = np.array(list(nx.get_node_attributes(G,"weight").values()))
node_size = node_size*scalingfactor_node
nx.draw(G,
font_family = "MS Gothic",
with_labels = True,
width= edge_weights,
node_size = node_size,
font_color="white"
)
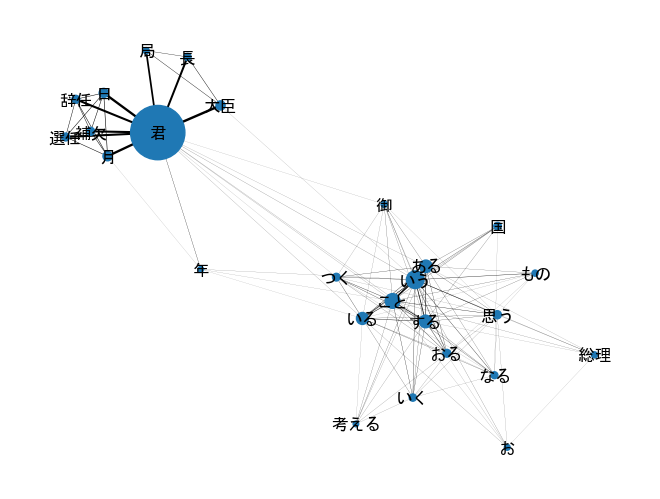
すべての可視化すると上記のようなおかしな図になってなんだかよくわかりません。そのため出現頻度が低いノード、それから共起が低いエッジを削除したいと思います。
ノードの150とエッジの50は、色々実験しながら決めました。
import copy
G2 = copy.deepcopy(G)
low_weight_nodes = [n for n,w in G2.nodes(data="weight") if w<=150]
G2.remove_nodes_from(low_weight_nodes)
low_weight_edges = [(u,v) for u,v,m in G2.edges(data="weight") if m<= 50]
G2.remove_edges_from(low_weight_edges)
G2.remove_nodes_from(list(nx.isolates(G2))) #孤立ノードを削除
scalingfactor_edge = 0.001
scalingfactor_node = 0.1
edge_weights = np.array(list(nx.get_edge_attributes(G2,"weight").values()))
edge_weights = edge_weights*scalingfactor_edge
node_size = np.array(list(nx.get_node_attributes(G2,"weight").values()))
node_size = node_size*scalingfactor_node
nx.draw(G2,
font_family = "MS Gothic",
with_labels = True,
width= edge_weights,
node_size = node_size,
font_color="black"
)
不要な語がたくさん入ってしまっていました。ストップワードを考慮したコードにしてもう一回整理して実行してみます。
stopwords=["もの"
"こと",
"よう",
"ところ",
"令和",
"ふう",
"する",
"いる",
"おく",
"もの",
"くる",
"おる",
"つく",
"お",
"意見",
"ある",
"いう",
"よう",
"なる",
"ほう",
"いただく",
"こと",
"ござる",
"ところ",
"思う",
"令和",
"第",
"年",
"月",
"さん",
"君",
"等",
"御",
]
sentences = text.split("。")
import spacy
nlp = spacy.load("ja_ginza")
sentence_list = list()
for sentence in sentences:
doc = nlp(sentence)
tokenlist = list()
for sent in doc.sents:
for token in sent:
if token.pos_ in ["PROPN","NOUN","VERB","ADJ"]:
if token.lemma_ not in stopwords:
tokenlist.append(token.lemma_)
sentence_list.append(" ".join(tokenlist))ここまで40秒
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(token_pattern=r'(?u)\b\w+\b')
x = vectorizer.fit_transform(sentence_list)
import pandas as pd
kyoki = pd.DataFrame(np.dot(x.T,x).todense(),
index=vectorizer.get_feature_names_out(),
columns = vectorizer.get_feature_names_out())
edge_list = list()
node_list = list()
num_word = len(kyoki)
for row in range(num_word):
for col in range(num_word):
if row<col:
if kyoki.iloc[row,col]!=0:
edge_list.append((kyoki.index[row],
kyoki.columns[col],
{"weight":int(kyoki.iloc[row,col])}
))
elif row == col:
node_list.append((kyoki.index[row],
{"weight":int(kyoki.iloc[row,col])}
))これだけで4分
scalingfactor_edge=0.03
scalingfactor_node=0.7
edge_weight_cutoff = 76
node_weight_cutoff = 13
import networkx as nx
G = nx.Graph()
G.add_edges_from(edge_list)
G.add_nodes_from(node_list)
low_weight_nodes = [n for n,w in G.nodes(data="weight") if w<=edge_weight_cutoff]
G.remove_nodes_from(low_weight_nodes)
low_weight_edges = [(u,v) for u,v,m in G.edges(data="weight") if m<= node_weight_cutoff]
G.remove_edges_from(low_weight_edges)
if low_weight_edges:
G.remove_edges_from(low_weight_edges)
G.remove_nodes_from(list(nx.isolates(G))) #孤立ノードを削除
edge_weights = np.array(list(nx.get_edge_attributes(G,"weight").values()))
edge_weights = edge_weights*scalingfactor_edge
node_size = np.array(list(nx.get_node_attributes(G,"weight").values()))
node_size = node_size*scalingfactor_node
fig = nx.draw(G,
font_family = "MS Gothic",
with_labels = True,
width= edge_weights,
node_size = node_size,
font_color="black"
)
ここは早い0.6秒
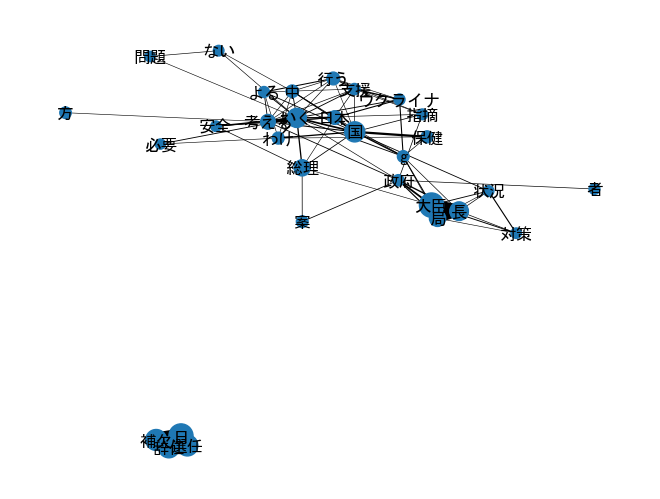
pyvisを用いる
scalingfactor_edge_pyvis =0.001
scalingfactor_node_pyvis=0.001
from pyvis.network import Network
nt = Network(width ='800px',
height='800px',
notebook=True)
for node,attrs in G.nodes(data=True):
nt.add_node(node,title=node,size=30*attrs["weight"]*scalingfactor_node_pyvis,font_size=50)
for node1,node2,attrs in G.edges(data=True):
nt.add_edge(node1,node2,width=20*attrs["weight"]*scalingfactor_edge_pyvis)
nt.show_buttons()
nt.show("mynetwork.html")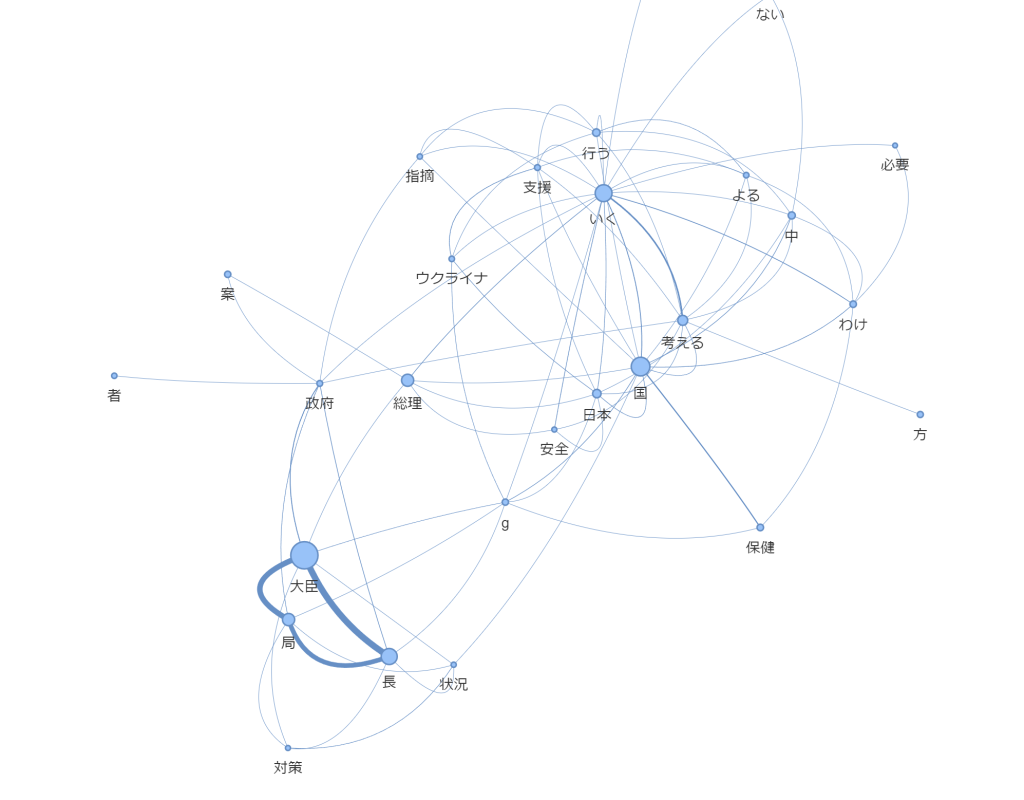
単語が短くなってしまって意味が分かりにくいところもあるので、matcherを使ったりすればもっと良くなると思います。
matcherを使った場合(名詞*2 ~4の単語、動詞のみを取得)
stopwords=["もの"
"こと",
"よう",
"ところ",
"令和",
"ふう",
"する",
"いる",
"おく",
"もの",
"くる",
"おる",
"つく",
"お",
"意見",
"ある",
"いう",
"よう",
"なる",
"ほう",
"いただく",
"こと",
"ござる",
"ところ",
"思う",
"令和",
"第",
"年",
"月",
"さん",
"君",
"等",
"御",
]
sentences = text.split("。")
from spacy.matcher import Matcher
import spacy
nlp = spacy.load("ja_ginza")
matcher = Matcher(nlp.vocab)
patterns = [
[{'POS':'NOUN'}],
[{'POS':'NOUN'},{'POS':'NOUN'}],
[{'POS':'NOUN'},{'POS':'NOUN'},{'POS':'NOUN'}],
[{'POS':'NOUN'},{'POS':'NOUN'},{'POS':'NOUN'},{'POS':'NOUN'}],
[{'POS':'VERB'}],
]
for pattern in patterns:
name = f'noun_phrase_{len(pattern)}'
matcher.add(name,[pattern])
sentence_list = list()
for sentence in sentences:
doc = nlp(sentence)
tokenlist = list()
mydict = dict()
mydict["start"] = [0,0]
for _,begin,end in matcher(doc):
mydict[doc[begin:end].lemma_] = [begin,end]
mydict["last"] = [len(doc),len(doc)]
pre_begin = 0
pre_end = 0
for key,value in mydict.items():
if pre_end < value[0]:
thisword = doc[pre_begin:pre_end].lemma_
if thisword not in stopwords:
tokenlist.append(thisword)
pre_begin = value[0]
pre_end = value[1]
else:
pre_end = value[1]
sentence_list.append(" ".join(tokenlist))