
- Neural NetworkとTensorflowについて
- 画像の処理について(今回記事)
- CNNの学習(Keras)について
- Google Colabについて
- AutoKerasについて
数字を認識するConvolutional Neural Networkをkerasで作っていきます。まずは学習データを作ります。これだけで結構な苦労です。CNNだけを勉強したいなら、mnistの手書きデータをimportすれば、すぐにCNNの学習に進めます。ただ、自分で学習データを作ることにこだわりたいと思います。
取られた写真を画像加工して機械学習にちょうどいい形に持っていきます。そのために画像加工の技術を身につけなければなりません。言語はpythonを使用し、ライブラリはopencv-pythonを使用します。
1 目的の領域を切り出す
例えば、以下のような問診票の記入欄があるとします。もしくは、麻酔モニターの画像だとします。このままだと、機械学習にもっていくことはできません。なぜなら、クラス分けがとんでもない数になります。7桁数字なので、1000000通りのクラス分けをする必要があります。


考え方を変えて、1桁1桁を判別する問題と捉えると10通り(0,1,2,3,4,5,6,7,8,9)のクラス分け問題になります。そうすると、1桁1桁分離した画像を入手する必要があります。でもどうやって?そこでアフィン変換という画像加工が必要です。アフィン変換をすると、以下のような画像の切り出しができます。
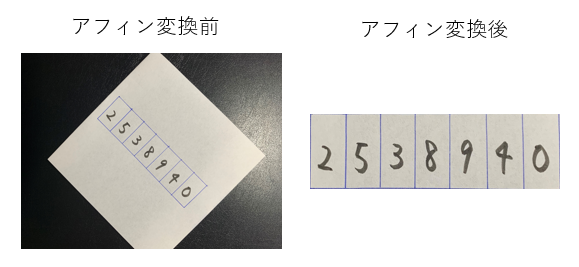
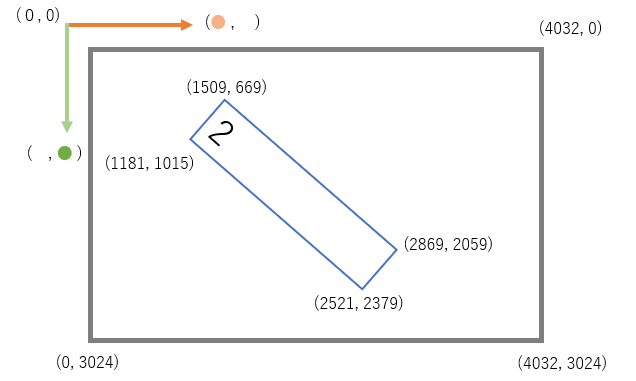
アフィン変換をするには、画像上のポイントとなる4つの座標が必要です。この場合は、青枠の4隅です。座標とは、ここではピクセルです。座標を知るには、win標準のペイントでひらいて画像の上にマウスを持っていきます。すると左下に表示されます。青枠の左下の座標は(1185, 1109)だとわかります。また、右下にはこの画像のピクセル数(4032, 3024)が記載があります。
調べてみると、以下の座標関係があることがわかりました。
アフィン変換を実施すると以下のような形になります。青枠の4点を引っ張って、画像の枠に引っ掛けて虫ピンを止めたようなイメージです。
アフィン変換を実施するには、以下のコードです。numpyとopencvが必要です。持っていない場合には、pip install numpy pipとinstall opencv-pythonをしてください。
import cv2
import numpy as np
img = cv2.imread(r"C:\Users\tegaki_1.jpg")
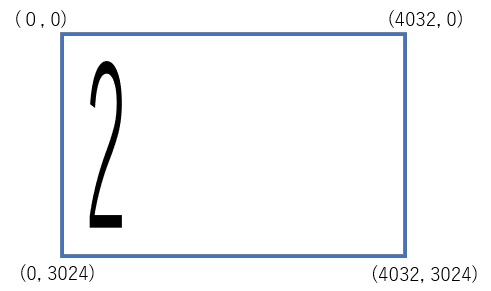
src_points = np.float32([[1509,669], [2869,2059], [1181,1015],[2521,2379]])
dst_points = np.float32([[0,0], [4032,0], [0,3024], [4032,3024]])
projective_matrix = cv2.getPerspectiveTransform(src_points, dst_points)
img_output = cv2.warpPerspective(img, projective_matrix, (4032,3024))
cv2.imwrite(r"C:\Users\tegaki_1_affine.jpg",img_output)src_pointsで、青枠の座標を指定します。左上、右上、左下、右下の順番で指定します。dst_pointsは、元の座標の左上、右上、左下、右下を指定します。その下は、変換に使う行列を作成です。その下は行列を使って、画像を変換します。
結果、以下のような画像が出来上がりました。

もとの画像のアスペクト比を引き継いでいるため縦に伸びてしまいました。今度は、ちょうどいい感じにresizeします。機械的学習的には、この作業はいらないのかもしれませんが、人間的にはちょっと飲めません。
横1000ピクセル、縦300ピクセルの画像に変換します。

以下がコードです。
import cv2
import numpy as np
img = cv2.imread(r"C:\Users\tegaki_1.jpg")
src_points = np.float32([[1509,669], [2869,2059], [1181,1015],[2521,2379]])
dst_points = np.float32([[0,0], [4032,0], [0,3024], [4032,3024]])
projective_matrix = cv2.getPerspectiveTransform(src_points, dst_points)
img_output = cv2.warpPerspective(img, projective_matrix, (4032,3024))
halfImg = cv2.resize(img_output, (1000,300))
cv2.imwrite(r"C:\Users\tegaki_1_affine_resize.jpg",halfImg)以下の画像ができました。

今度は、それぞれの桁に切り出しです。幅÷7をすることで、1つの枠の幅を得ることができます。試しに、一番左の2を取り出してみます。
上記の画像は、(300, 1000)ピクセルの画像なので、1000÷7をすることで幅がわかります。cv2で読み込んだ画像は、(300,1000,3)のnumpy arrayの形をしています。最後の3は、BGR(RGBと順番が違うだけ)ごとに1枚の画像があることを示しています。幅で画像を切るには、真ん中の軸をスライスします。
import cv2
img = cv2.imread(r"C:\Users\tegaki_1_affine_resize.jpg")
divpoint1 = int(1000/7) # int(img.shape[1]/7)でもよい
img_1 = img[:,:divpoint1,:]
cv2.imwrite(r"C:\Users\tegaki_1_divided.jpg",img_1)
cv2を使うところは終わりました。もうすでに、お腹一杯です。
2 学習データを増やす
さきほど作った画像を自分の目で数字を判定し、数字ごとにフォルダに入れます。どれだけの枚数を用意すればいいのかというのは難しい問題です。多ければ多いほうがいいです。次のステップで画像の水増しを行いますのでそこまで頑張らなくてもいいと思います。
今、2という名前のフォルダにたくさんの2の画像が入っているとします。その画像をもとに水増しを行います。今度は、tensorflowが必要になります。pip install tensorflowをしてください。
tensorflowのImageDataGeneratorという機能を使います。これは、元の画像を少し移動したり拡大したり縮小したり暗くしたり等の加工をして別の画像を作る機能です。以下のコードではパラメーターとして、以下を渡しています。試行錯誤で調整しながらちょうどいいパラメーターを探してください。
rotation_range=5, # 回転
zoom_range=[0.9,1.0], # ズーム
shear_range=5, # 斜め変形
width_shift_range=[-1,1] # 横移動
設定可能なパラーメーターは、以下で見ることができます。
https://keras.io/ja/preprocessing/image/
以下をコードは、2フォルダ内の1枚1枚を使って、2フォルダ内に一気に変形画像を保存するコードです。
1枚の画像から何枚の画像を作るかというのは、for i in range(50):のrange内の数字で決まります。100枚でも1000枚でも作れます。
from numpy import expand_dims
from tensorflow.keras.preprocessing.image import load_img, img_to_array, ImageDataGenerator
import cv2
import glob
paths = glob.glob(r"C:\Users\2\*.jpg")
s = 1
def saveimage(k,data):
global s
cv2.imwrite("C:\\Users\\2\\{0}_{1}.jpg".format(s,k),data)
for path in paths:
# load the image
img = load_img(path)
# convert to numpy array
data = img_to_array(img)
# expand dimension to one sample
samples = expand_dims(data, 0)
# create image data augmentation generator
datagen = ImageDataGenerator(rotation_range=5,
zoom_range=[0.9,1.0],
shear_range=5,
width_shift_range=[-1,1]
)
# prepare iterator
it = datagen.flow(samples, batch_size=1)
# generate samples
for i in range(50):
# generate batch of images
batch = it.next()
# convert to unsigned integers for viewing
image = batch[0].astype('uint8')
saveimage( (i+1) ,image)
s += 1
これで各数字のフォルダ内に5000枚くらい作れたでしょうか。
3 画像をnumpy arrayにする
つぎは、画像からtensorflowに学習させるためのnumpy arrayを作成します。npyファイルを作ります。
import random
import glob
import numpy as np
from tensorflow.keras import utils
from tensorflow.keras.preprocessing.image import load_img, img_to_array
img_rows = 150 # 縦ピクセル
img_cols = 300 # 横ピクセル
classlist = ["0","1","2","3","4","5","6","7","8","9"]
nb_classes = 10 # class数
test_size = 1000 # 何枚テスト用にするか
train_size = 5000 # 何枚訓練用にするか
# 画像スタック用の配列
X_train = []
Y_train = []
X_test = []
Y_test = []
for i,myclass in enumerate(classlist):
img_files = glob.glob(f"C:\\Users\\{myclass}\\*.jpg") # ディレクトリ内の画像ファイルを全部読み込む
random.shuffle(img_files)
for k, img_file in enumerate(img_files): # ディレクトリ内の全ファイルに対して
img = load_img(img_file, target_size=(img_rows,img_cols))
x = img_to_array(img)
x = x.astype('float32')
x = x/255 # scaling
if k < test_size:
X_test.append(x) # testデータに画像配列追加
Y_test.append(i) # testデータ(正解ラベル)にクラス番号を追加
elif test_size <= k <= (test_size + train_size -1):
X_train.append(x) # trainデータに画像配列追加
Y_train.append(i) # trainデータ(正解ラベル)にクラス番号を追加
# 学習、テストデータをlistからnumpy.ndarrayに変換
X_train = np.array(X_train, dtype='float')
Y_train = np.array(Y_train, dtype='int')
X_test = np.array(X_test, dtype='float')
Y_test = np.array(Y_test, dtype='int')
# カテゴリカルデータ(ベクトル)に変換
Y_train = utils.to_categorical(Y_train, nb_classes)
Y_test = utils.to_categorical(Y_test, nb_classes)
# 画像の順番をシャッフルする
id_train = np.random.choice(np.arange(X_train.shape[0]), X_train.shape[0], replace=False)
X_train = X_train[id_train]
Y_train = Y_train[id_train]
id_test = np.random.choice(np.arange(X_test.shape[0]), X_test.shape[0], replace=False)
X_test = X_test[id_test]
Y_test = Y_test[id_test]
# 作成した学習データ、テストデータをファイル保存
np.save("C:\\Users\\X_train.npy", X_train)
np.save("C:\\Users\\X_test.npy", X_test)
np.save("C:\\Users\\Y_train.npy", Y_train)
np.save("C:\\Users\\Y_test.npy", Y_test)
# 念のため作成したデータの型を表示
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)img_rows = 150 # 縦ピクセル
img_cols = 300 # 横ピクセル
これらは元の画像の形を調べて、その形でいいと思います。もし転移学習(transfer learning)を考えている場合には、そのモデルが受け取る形を指定しておきます。多いのは、224、224の形です。しっかり確認しないと後でめんどくさいです。転移学習を使わない場合は好きなサイズでいいです。
x = x/255は、画像の数値が0~255まであるところを0~1の間にスケーリングします。これにより、RGB色間の数字の大きさに影響をうけなくなります。
カテゴリカルデータ(ベクトル)に変換は、ダミー変数と同様です。通常のダミー変数と違って、カテゴリごとに1列あります。よって、10カテゴリでは10列になります。Neural Networkに学習させるために必要なデータの形です。
画像の順番をシャッフルするのはとても重要です。最初のころCNNに学習させてもval_accが全然上がらない現象に陥り、なぜだか全然わかりませんでした。これは、画像の順番をシャッフルしていなかったからです。シャッフルしない状態だと、カテゴリーごとに画像が順番に並んでいる状況です。(111111222222・・・)これで学習させると、バッチ内がすべて同じカテゴリになってしまうので学習がうまくいかないのです。これをシャッフルして(9154938747463・・・)とします。MNISTのデータセットはすべてシャッフルされたデータを入手できるので、このステップを意識することはありません。自分でやることで発見できた重要な点です。
最後のshapeは以下がプリントされます。
訓練データ
X_train.shape : (50000, 150, 300, 3) 5000枚×10カテゴリ,ピクセル幅,ピクセル高さ,BGR
Y_train.shape : (50000, 10) 5000枚×10カテゴリ, ダミー列
テストデータ
X_test.shape : (1000, 150, 300, 3)
Y_test.shape : (1000, 10)