
Rとpythonはデータサイエンスに使用される言語のトップ2です。どちらの言語が好きかで、team Rとteam pythonに所属します。私はどちらかといえば、team Rです。
team python側に立てば、pythonはデータサイエンス系もできるし、それ以外でもなんでもできる。パッケージも多い。最新のアルゴリズムはpythonでまず初めに実装される。
team R側に立てば、Rはパッケージ管理が簡単。pythonは何をするにもパッケージが必要で、パッケージ間に使い方の一貫性がない。dplyrのデータ操作性の良さ、ggplotのグラフ作成のしやすさ、Rstudioの使いやすさは最強。
私はできるだけR側で操作したいという気持ちがあります。最近いくつかの発見があり、R側の良さをpython側で再現できることがわかってきました。もし、最初から知っていたらもっと楽だったな~と強く思うので、勉強の順番がR→pythonの人にはぜひとも共有したいです。
- Rのcheat sheet文化がpythonでも存在している
- データ操作にはdfplyを使え(dplyrに相当)
- グラフ作成にはplotnineを使え(ggplotに相当)
- エディタはspyderを使え(Rstudioに相当)
1.Rのcheat sheet文化がpythonでも存在している
早く知っていれば、pandaに泣かされる時間は激減していたことでしょう。
Rにはggplot2をはじめ様々なパッケージに、cheatsheetというパッケージの操作を1枚から2枚にまとめたPDFが存在しています。これが要点を抑えており、とてもとても便利なのです。
pythonを勉強する際にpandasのオブジェクト指向の書き方には泣かされました。オブジェクトの後にメソッドがあったり、逆にクラスメソッドで今度はpdから始まったり、、、Rのようにprocedure oriented programmingの方が好きです。毎回ググったり前のコードみたりして行き当たりばったりでこなしてきましたが、以下のチートシートがあると知り、愕然としました。早く知っていれば!!
https://github.com/pandas-dev/pandas/blob/master/doc/cheatsheet/Pandas_Cheat_Sheet.pdf
numpy、seaborn、matplotlib、kerasまでcheat sheetが存在しています。ググればすぐに出てきますので是非ご活用を!
2.データ操作にはdfplyを使え(dplyrに相当)
私は、pandasのデータ操作が苦手です(した)。pandasのエラーに感情が高ぶりすぎると、いったんRのtidyverseで加工してcsvにしてからまたpythonみたいなこともあったようななかったような。
ただ、このパッケージを知ってからはそんなことはなくなりました。その名もdfply。dplyrと同じ機能です。もはや名前も一緒にしてほしかったです。使い方は、公式のgithubにわかりやすく書かれています。
https://github.com/kieferk/dfply
変数は、X.変数名、又は、X[“変数名“]で指定します。Xはエックスの大文字です。変数名にスペースがあると前者だと認識できないので後者を統一的に使うといいと思います。%/% は >>になっています。( )で全部を囲えば、改行も問題ないです。
原則として避けた方がよいとされているfrom dfply import * の書き方をしてください。この書き方はdfplyパッケージの関数をすべてメモリーに乗せて、dfply. ●●という書き方をしなくて済むようになり、Rっぽい書き方ができます。他のパッケージの関数名と衝突する可能性があることを頭の片隅に置いておく必要があります。
使い方をいくつか紹介
from dfply import *
diamonds >> select(X[“carat”])
diamonds >> mutate(new_var=X.price + X.depth)
diamonds >> mask(X.cut == 'Ideal') # filter_byと同じ
diamonds >> groupby(X.cut) >> summarize(price_n=n(X.price))
diamonds >> groupby(X.cut) >> summarize(price_ndistinct=n_distinct(X.price))
diamonds >> group_by('cut') >> summarize(price_mean=X.price.mean())
diamonds >> group_by('cut') >> summarize(price_sum=X.price.sum())
# melt(wide to long) in R の代替 gather(key, value, [崩す列])
diamonds >> gather('variable', 'value', ['price', 'depth'])
#dcast (long to wide) in R の代替 spread(key, values, convert=True
)
# convertないとdatatypeが全部objectになる。_IDという列が必要。
long = long >> mutate(_ID = range(0,len(long)))
widened = long >> spread(X.variable, X.value)
# table in R の代替 crosstab 一度、関数をセットする必要あり
@dfpipe
def crosstab(df, index, columns):
return pd.crosstab(index, columns)
diamonds >> crosstab(X.cut, X.color)reshape2のdcastとmeltも実現できます。また、Rのtableの機能をcrosstabで実現できます。
3.グラフ作成にはplotnineを使え(ggplotに相当)
matplotlibの書き方が2種類あるのが悪いと思うんですが、matplotlibでなかなかやりたいことができません。ggplotに慣れているのであれば、plotnineをお勧めします。使い方はggplotそのものです。変数名に” ”を付けること、全部をかっこでくくること、という2点を抑えておけばそのままggplotです。実はggplotというpythonのパッケージがあるのですが、開発が2016年で止まっています。
これも、原則として避けた方がよいとされているimport *をしてください。Rの使用感を得られます。また、今回はplotnineに付属しているデータmsleepを使用します。plotnineをimportすればdataオブジェクトを取り出せるのですが、dfplyのデータオブジェクトと衝突してしまいます。そのため、from plotnine import data as pdataとしています。
from plotnine import *
from plotnine import data as pdata
msleep = pdata.msleep
(ggplot(msleep, aes(x="brainwt",
y="sleep_total",
size="bodywt",
fill = "bodywt"))+
geom_point()+
scale_fill_gradient2(low="blue",high="pink",midpoint=4000)
)
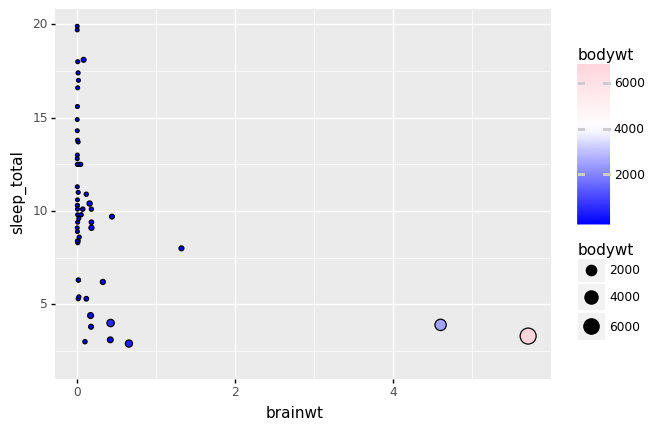
信じられないくらいggplotそのままじゃないですか?()でくくって、変数は””で囲うことさえすればそのままです。使えるthemeは、以下の通りです。
theme_538()
theme_bw()
theme_classic()
theme_dark()
theme_gray(), theme_grey()
theme_light()
theme_linedraw()
theme_matplotlib()
theme_minimal()
theme_seaborn()
theme_void()
theme_xkcd()
https://plotnine.readthedocs.io/en/stable/api.html
4.エディタはspyderを使え(Rstudioに相当)
jupyter notebookを使っていると、いまいち変数の中身がどうなっているかよくわからないです。私のコードは、確認のための無駄な行が多くなったりして、見づらくなります。Rstudioみたいに1行ずつ実行できて、かつ変数が見れるパネルが欲しい。。そうです、spyderの出番です。最初、名前が嫌で嫌煙していましたが使い勝手はまさにRstudioです。
仮想環境を使っていない人ならspyderを直でダウンロードして使ってもいいと思います。仮想環境を使う場合にはAnacondaをダウンロードして、Anaconda Navigatorの中で仮想環境を変更してからspyderを起動するという方法しかないようです。欠点は、Anacondaの起動に時間がかかるので、anaconda promptから起動した方が早いです。
conda activate 〇〇
(〇〇)spyder
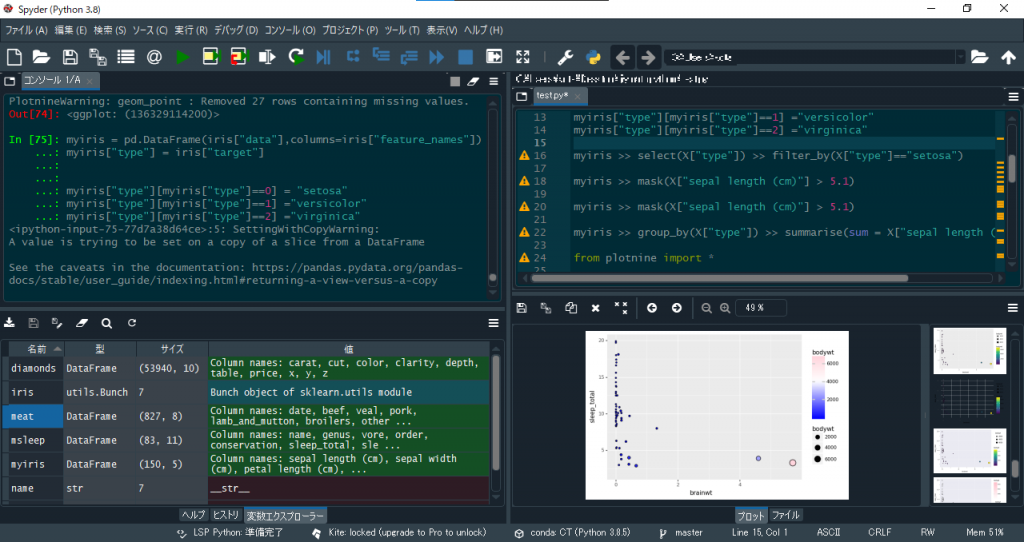
左下の変数エクスプローラーを見れば、変数の中身を見れます。さらに、ダブルクリックすれば中身の詳細がみれます。あと、データを選択してコピーすることもできます。列名がコピーできないのが惜しいです。
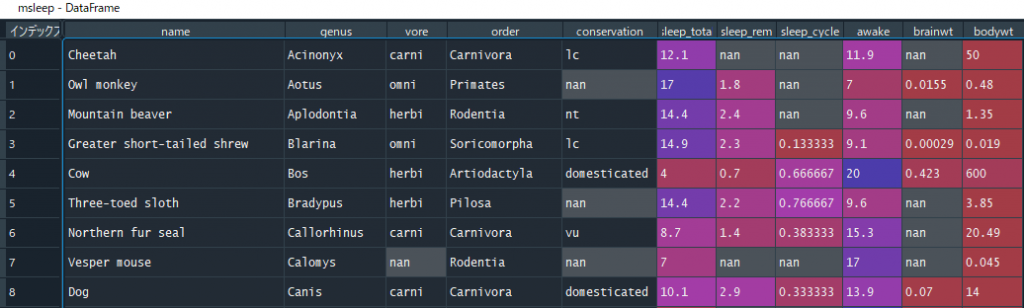
パネルの位置をカスタマイズするには、Contrl + Shift + F5を押します。
1行ずつ実行をRstudioと同じようにControl + Enterにするには、設定からrun selectionのショートカットを変更します。
ブレークポイントを設定してデバッグもできます。