
時系列データについて
株、気温、為替、感染症数、多くのものがTimeSeriesデータ(時系列データ)です。TimeSeriesデータと、その他のデータを区別するものはデータに時間の方向性があるかないかという点です。TimeSeriesでは、昨日の数値が今日の数値に強く影響します。そのため、変数に過去の自分自身を入れることが有効です。
AutoMLについて
モデルの選択といった作業は、TimeSeries以外のデータの機械学習と同じです。モデル選択は非常に煩雑な作業ですが、AutoMLという複数のモデルを自動で試してくれるアルゴリズムが出てきました。これにより自分で1つづつモデリングして地道に比較をする作業がなくなりました。
しかし今度はAutoML自体が複数出てきたため、AutoMLの選択という作業が生じているように感じます。嬉しい悲鳴?ということでしょうか。そのAutoMLの比較をしていきたいと思います。
データについて
ハンガリーにおけるchikenpox(水疱瘡)のデータを用います。データセットはUCI Machine learning repositoryから入手します。鶏の鶏痘だと思ったけど人の水疱瘡の数だった。。
https://archive.ics.uci.edu/ml/datasets/Hungarian+Chickenpox+Cases
地域ごとに、患者数が記載されています。期間は、03/01/2005 ~ 29/12/2014で、1週間ごとのデータです。BUTAPESTの患者数を予想します。最後の3か月分(13 record分)を予想したいと思います。
まずはデータの読み込みとグラフを作ります。
# from google.colab import drive
# drive.mount("/content/drive")
import pandas as pd
import numpy as np
!pip install dfply
from dfply import *
df = pd.read_csv("/content/drive/MyDrive/hungary_chickenpox.csv")
df.head()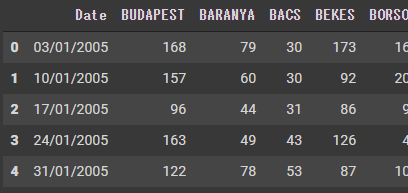
df2 = df >> select(X["Date"],X["BUDAPEST"])
df2["Date"] = pd.to_datetime(df2["Date"], format='%d/%m/%Y'))
import seaborn as sns
sns.lineplot(x=df2["Date"],y=df2["BUDAPEST"])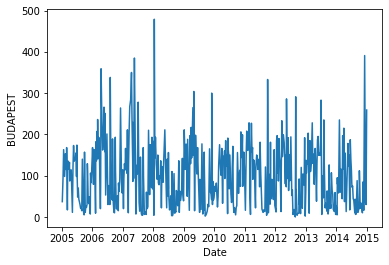
平均法
平均法は、今までの平均が将来も続くと予想します。一番ベーシックな予想です。最後の3か月(13レコード分)を予想してMAEを見ます。
result_mean = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true_value"])
split = len(df2) - 13
nrow = len(df2)
for i in range(split,nrow):
X_train = df2.iloc[0:i]
pred = X_train.mean(axis=0)
result_mean.iloc[i-(split),0] = pred.values
result_mean.iloc[i-(split),1] = df2.iloc[i,1]69.00
MAE69をベースとします。これより予想がよくないと、ダメです。
AUTOARIMA
Auto Arimaは、SARIMAモデルを自動で作ってくれるものです。Rのforecastパッケージが元になっているようです。
Auto Arimaをつかうためには、pmdarimaというパッケージを使用します。このモデルに読み込ませるためには、日付列がインデックスにする必要があります。そのため、一工夫します。
!pip install -q pmdarima
import pmdarima as pm次にデータを読み込ませます。
result_autoarima = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true_value"])
df_arima = df2.set_index(["Date"])
split = len(df_arima) - 13
nrow = len(df_arima)
for i in range(split,nrow):
X_train = df_arima.iloc[0:i]
arima_model = pm.auto_arima(X_train,
start_p=1, max_p=5, start_q=1, max_q=5,
start_P=1, max_P=5, start_Q=1, max_Q=5,
seasonal=True, D=10, max_D=10,
stepwise=True)
pred = arima_model.predict(n_periods=1, return_conf_int=False)
result_autoarima.iloc[i-(split),0] = pred[0]
result_autoarima.iloc[i-(split),1] = df_arima.iloc[i,0]
result_autoarima["mae"] = abs(result_autoarima["true_value"]-result_autoarima["pred"])
result_autoarima["mae"].mean()35.72
MAE 36は平均法の69に比べてだいぶ改善しました。
プロットして出来を見てみます。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
sns.lineplot(x=df2["Date"]>>head(-13),y=df2["BUDAPEST"]>>head(-13),color="blue")
sns.lineplot(x=df2["Date"]>>tail(13),y=df2["BUDAPEST"]>>tail(13),color="skyblue")
sns.lineplot(x =(df2["Date"]>>tail(13)).reset_index(drop=True),y=result_autoarima["pred"], color="pink")
ax.legend(["True value", "True value", "Predicted value"])
sns.set_theme(style="darkgrid")
plt.show()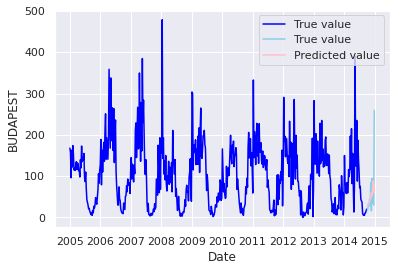
大事なところがよく見えないので、大事なところだけをスライスしてグラフ化します。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
sns.lineplot(x=df2["Date"] >>tail(50) >> head(-13),y=df2["BUDAPEST"]>> tail(50) >> head(-13),color="blue",legend='auto')
sns.lineplot(x=df2["Date"]>>tail(13),y=df2["BUDAPEST"]>>tail(13),color="skyblue",legend='auto')
sns.lineplot(x =(df2["Date"]>>tail(13)).reset_index(drop=True),y=result_autoarima["pred"], color="red",legend='auto')
ax.legend(["True value", "True value", "Predicted value"])
sns.set_theme(style="darkgrid")
plt.show()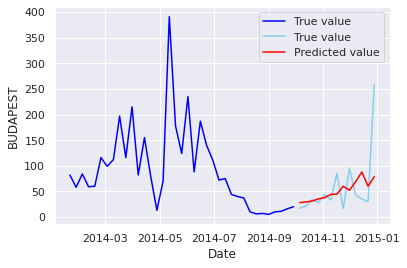
今後、他のAutoMLを試してみたいと思います。