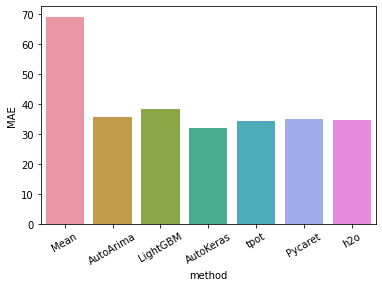前回の続きです。ハンガリーにおけるchikenpox(水疱瘡)のデータを使って、BUTAPESTにおける患者数の3か月分の予想を行っています。前前回は、AUTOARIMAでMAE36を叩き出しました。前回は、LightGBMでMAE38でした。今度は、AutoKerasを使って予想したいと思います。
Feature engineering
前回と同じですが、次の観測数値を、現在の観測数値と過去3レコード分の数値を使って予想します。
next = now + past1 + past2 + past3
そして日付列を整数順列にします。
df = pd.read_csv("/content/drive/MyDrive/hungary_chickenpox.csv")
df3 = df >> select(X["Date"],X["BUDAPEST"])
df3 = (df3 >>
mutate(next = lead(X["BUDAPEST"],1)) >>
mutate(past1 = lag(X["BUDAPEST"],1)) >>
mutate(past2 = lag(X["BUDAPEST"],2)) >>
mutate(past3 = lag(X["BUDAPEST"],3)) >>
tail(-3) >>
head(-1)
)
df4 = df3 >> select(~X["Date"])
df4 = df4.reset_index(drop=True)
df4 = df4.reset_index()
df4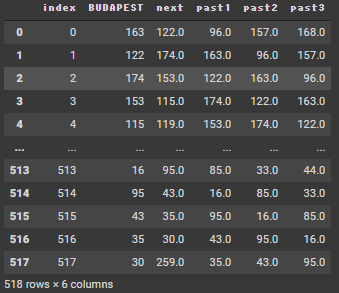
AutoKeras
Autokerasは、neural network(NN)のAutoMLです。NNの構造は、自由すぎて逆にどうすればいいのかわからないですが、AutoKerasでいい感じのを選んでくれます。GPUを使えますので計算早くできます。
必要パッケージをインストールします。
!pip -q install autokeras
!pip -q install tensorflow
import autokeras as akデータをtrain+validation とtestセットに分割します。直近3か月分(13レコード分)を予想したいので、train+validationは最後の13レコードを除いたものにします。また、target variable と explanation variable のデータフレームに分ける必要があります。
X_train_validation = (df4 >> select(~X["next"]))[:-13] # omit target and forecast period
y_train_validation = (df4 >> select(X["next"]))[:-13] # pick up target and omit forecast periodAutoKerasに学習してもらいます。
ak_model = ak.StructuredDataRegressor(max_trials=100,
overwrite=True,
metrics=['mae'])
ak_model.fit(X_train_validation, y_train_validation, epochs=200,validation_split=0.2)
""" モデルを保存・保存したものを読込む場合
# Evaluate the best model with testing data.
model_autokeras = reg.export_model()
model_autokeras.save("/content/drive/MyDrive/autokeras_model.h5")
from tensorflow.keras.models import load_model
ak_model = load_model("/content/drive/MyDrive/autokeras_model.h5",custom_objects=ak.CUSTOM_OBJECTS)
"""30分くらいで最適なNeural Networkの構成を見つけてくれます。
最適な構成で予測を行います。時系列データなので、1未来づつ予測します。autokerasのモデルは再学習可能なので、現在までのデータで逐次学習させます。
from tensorflow.keras.callbacks import ModelCheckpoint
result_AK = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true_diff"])
last30 = len(df4)-13
last = len(df4)
for i in range(last30,last):
X_train = (df4 >> select(~X["next"])).iloc[0:i]
y_train = (df4 >> select(X["next"])).iloc[0:i]
X_test = (df4 >> select(~X["next"])).iloc[i:i+1]
y_test = (df4 >> select(X["next"])).iloc[i:i+1]
checkpointer = ModelCheckpoint(filepath='logs',
verbose=1,
save_best_only=True)
ak_model.fit(x = X_train, y= y_train,
epochs = 50,
validation_split=0.1,
callbacks = [checkpointer])
pred = ak_model.predict(X_test)
result_AK.iloc[i-(last30),0] = float(pred)
result_AK.iloc[i-(last30),1] = y_test.values[0,0]
result_AK["mae"] = abs(result_AK["true_diff"]-result_AK["pred"])
result_AK["mae"].mean()31.8
MAE 31は今までで一番いいスコアがでました。今のところ、autoarima、lightGBM with optuna tuning よりもいいスコアです。
ちなみにNNの構造を見てみます。
from tensorflow.keras.utils import plot_model
plot_model(ak_model.export_model(), show_shapes=True, show_layer_names=True)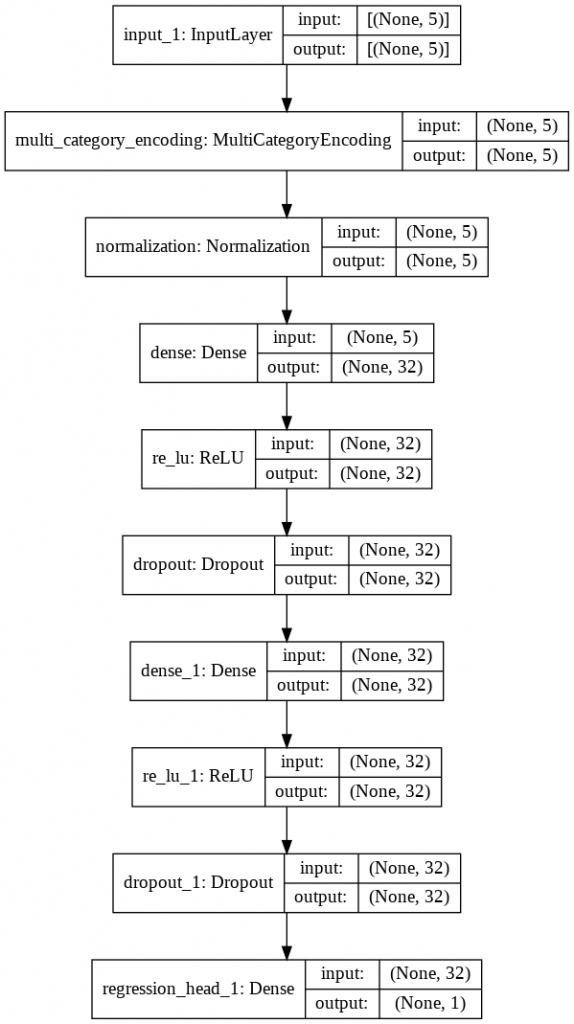
プロットしてみます。
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
sns.lineplot(x=df2["Date"] >> tail(-3) >> head(-1) >> tail(50) >> head(-13),y=df2["BUDAPEST"]>> tail(-3) >> head(-1) >> tail(50) >> head(-13),color="blue",legend='auto')
sns.lineplot(x=df2["Date"]>>tail(-3) >> head(-1) >> tail(13),y=df2["BUDAPEST"]>>tail(-3) >> head(-1) >>tail(13),color="skyblue",legend='auto')
sns.lineplot(x =(df2["Date"]>>tail(-3) >> head(-1) >> tail(13)).reset_index(drop=True),y=result_AK["pred"], color="red",legend='auto')
ax.legend(["True value", "True value", "Predicted value"])
sns.set_theme(style="darkgrid")
plt.show()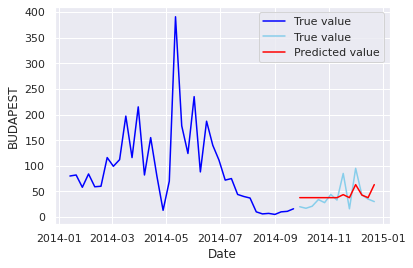
次は、tpotでAutoMLを実施します。