
前回の続きです。ハンガリーにおけるchikenpox(水疱瘡)のデータを使って、BUTAPESTにおける患者数の3か月分の予想を行っています。前回までの結果は、AUTOARIMAでMAE36、LightGBMでMAE38、AutokerasでMAE32、tpotでMAE34でした。
今回は、pycaretを使ってAutoMLをしたいと思います。
PyCaret
Rユーザーならピンとくるその名前、caret。関係ないとは言わせません。なぜcaretのAutoMLがpythonに来てしまったのでしょうか。
これは多機能なautoMLです。feature engeneering までやってくれるし、変数重要性とかも自動で出してくれます。すばらしいパッケージです。その実力やいかに。
まずインストールします。
!pip install pycaretこんなエラーがでたら、他のパッケージとconflictを起こしている可能性があります。ランタイムを初期化して、他のパッケージを読み込んでいない状態で実行すると乗り越えられました。
ERROR: pandas-profiling 2.11.0 has requirement requests>=2.24.0, but you’ll have requests 2.23.0 which is incompatible. ERROR: imbalanced-learn 0.8.0 has requirement scikit-learn>=0.24, but you’ll have scikit-learn 0.23.2 which is incompatible. ERROR: pyldavis 3.3.1 has requirement numpy>=1.20.0, but you’ll have numpy 1.19.5 which is incompatible. ERROR: pyldavis 3.3.1 has requirement pandas>=1.2.0, but you’ll have pandas 1.1.5 which is incompatible. ERROR: phik 0.11.2 has requirement scipy>=1.5.2, but you’ll have scipy 1.4.1 which is incompatible.
使うデータは前回までのと一緒です。自分でfeature engeneeringしてこんな形をしています。
nextの値を、index+now + past1 + past2 + past3で予測します。
データをpycaret用に変換する必要があります。それに合わせて、feature engeneeringを実施してくれます。targetに目的変数をセットします。
from pycaret.regression import *
caretdata = setup(df4, target = "next")変数のデータタイプがあっているか聞いてくるので合っていたらEnterをおします。
下のコマンドで複数のモデルを比較してくれます。なんとなくパラメーターを渡したり、オブジェクトの後にメソッドを書きたくなりますが、これだけでいいです。
best = compare_models()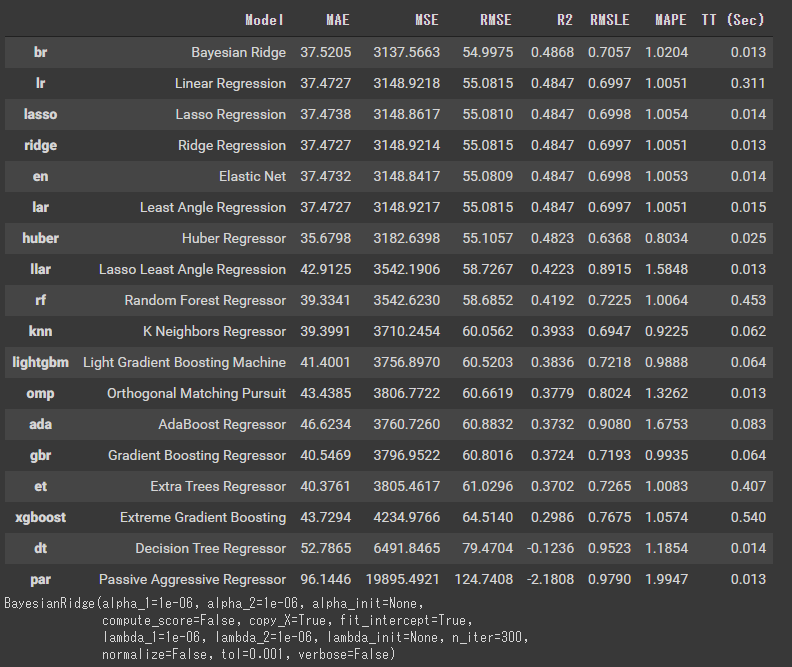
モデルを見てみます。
bestBayesianRidge(alpha_1=1e-06, alpha_2=1e-06, alpha_init=None,
compute_score=False, copy_X=True, fit_intercept=True,
lambda_1=1e-06, lambda_2=1e-06, lambda_init=None, n_iter=300,
normalize=False, tol=0.001, verbose=False)
自分の好きな指標に合わせてチューニングしてくれます。
best_tuned = tune_model(best, optimize = "MAE")
best_tunedBayesianRidge(alpha_1=0.3, alpha_2=0.0001, alpha_init=None, compute_score=True, copy_X=True, fit_intercept=False, lambda_1=0.05, lambda_2=0.2, lambda_init=None, n_iter=300, normalize=False, tol=0.001, verbose=False)
このモデルのクラスは、sklearnです。
type(best_tuned)sklearn.linear_model._bayes.BayesianRidge
時系列データなので、1未来づつ予測します。現在までのレコードで、再学習させます。fit、predictの使い方はsklearnの使い方と同じです。
result_caret = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true_diff"])
last30 = len(df4)-13
last = len(df4)
for i in range(last30,last):
X_train = (df4 >> select(~X["next"])).iloc[0:i]
y_train = (df4 >> select(X["next"])).iloc[0:i]
X_test = (df4 >> select(~X["next"])).iloc[i:i+1]
y_test = (df4 >> select(X["next"])).iloc[i:i+1]
refit = best_tuned.fit(X_train,y_train)
pred = refit.predict(X_test)
result_caret.iloc[i-(last30),0] = pred[0]
result_caret.iloc[i-(last30),1] = y_test.values[0,0]
result_caret["mae"] = abs(result_caret["true_diff"]-result_caret["pred"])
result_caret["mae"].mean()34.91
MAE35、うーん微妙でした。結局は、sklearnです。
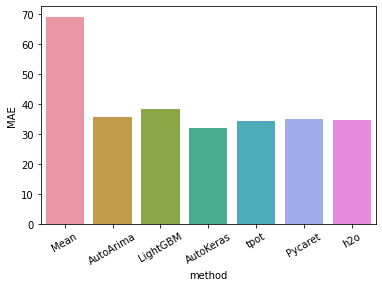
つぎは、H2Oを使って予測します。