sklearnのutilsにall_estimatorsという関数があります。これでtype_filterをするとregressorを全部取得できることがわかりました。ちまちま普段使いのregressorを当てていかなくても自動で全部当ててくれます。
ちなみにauto-sklearnというautoMLライブラリがありますが、これは工夫なしではwindowsで動きません。ただ単にsklearnの中でいいやつを探したいライトユースのautoMLなら自分で書いてしまいましょう。
sklearn all_estimatorsで取得できるモデルについて
all_estimatorsの引数type_filterにregressorを渡します
注:all_estimatorsは1.2.2では以下のように場所が変更されています
from sklearn.utils.discovery import all_estimators
from sklearn.utils import all_estimators
# scikit-learn 1.2.2では from sklearn.utils.discovery import all_estimators
all_estimators(type_filter="regressor")[(‘ARDRegression’, sklearn.linear_model._bayes.ARDRegression),
(‘AdaBoostRegressor’, sklearn.ensemble._weight_boosting.AdaBoostRegressor),
(‘BaggingRegressor’, sklearn.ensemble._bagging.BaggingRegressor),
(‘BayesianRidge’, sklearn.linear_model._bayes.BayesianRidge),
(‘CCA’, sklearn.cross_decomposition._pls.CCA),
(‘DecisionTreeRegressor’, sklearn.tree._classes.DecisionTreeRegressor),
(‘DummyRegressor’, sklearn.dummy.DummyRegressor),
(‘ElasticNet’, sklearn.linear_model._coordinate_descent.ElasticNet),
(‘ElasticNetCV’, sklearn.linear_model._coordinate_descent.ElasticNetCV),
(‘ExtraTreeRegressor’, sklearn.tree._classes.ExtraTreeRegressor),
(‘ExtraTreesRegressor’, sklearn.ensemble._forest.ExtraTreesRegressor),
(‘GammaRegressor’, sklearn.linear_model._glm.glm.GammaRegressor),
(‘GaussianProcessRegressor’,
sklearn.gaussian_process._gpr.GaussianProcessRegressor),
(‘GradientBoostingRegressor’, sklearn.ensemble._gb.GradientBoostingRegressor),
(‘HistGradientBoostingRegressor’,
sklearn.ensemble._hist_gradient_boosting.gradient_boosting.HistGradientBoostingRegressor),
(‘HuberRegressor’, sklearn.linear_model._huber.HuberRegressor),
(‘IsotonicRegression’, sklearn.isotonic.IsotonicRegression),
(‘KNeighborsRegressor’, sklearn.neighbors._regression.KNeighborsRegressor),
(‘KernelRidge’, sklearn.kernel_ridge.KernelRidge),
(‘Lars’, sklearn.linear_model._least_angle.Lars),
(‘LarsCV’, sklearn.linear_model._least_angle.LarsCV),
(‘Lasso’, sklearn.linear_model._coordinate_descent.Lasso),
(‘LassoCV’, sklearn.linear_model._coordinate_descent.LassoCV),
(‘LassoLars’, sklearn.linear_model._least_angle.LassoLars),
(‘LassoLarsCV’, sklearn.linear_model._least_angle.LassoLarsCV),
(‘LassoLarsIC’, sklearn.linear_model._least_angle.LassoLarsIC),
(‘LinearRegression’, sklearn.linear_model._base.LinearRegression),
(‘LinearSVR’, sklearn.svm._classes.LinearSVR),
(‘MLPRegressor’, sklearn.neural_network._multilayer_perceptron.MLPRegressor),
(‘MultiOutputRegressor’, sklearn.multioutput.MultiOutputRegressor),
(‘MultiTaskElasticNet’,
sklearn.linear_model._coordinate_descent.MultiTaskElasticNet),
(‘MultiTaskElasticNetCV’,
sklearn.linear_model._coordinate_descent.MultiTaskElasticNetCV),
(‘MultiTaskLasso’, sklearn.linear_model._coordinate_descent.MultiTaskLasso),
(‘MultiTaskLassoCV’,
sklearn.linear_model._coordinate_descent.MultiTaskLassoCV),
(‘NuSVR’, sklearn.svm._classes.NuSVR),
(‘OrthogonalMatchingPursuit’,
sklearn.linear_model._omp.OrthogonalMatchingPursuit),
(‘OrthogonalMatchingPursuitCV’,
sklearn.linear_model._omp.OrthogonalMatchingPursuitCV),
(‘PLSCanonical’, sklearn.cross_decomposition._pls.PLSCanonical),
(‘PLSRegression’, sklearn.cross_decomposition._pls.PLSRegression),
(‘PassiveAggressiveRegressor’,
sklearn.linear_model._passive_aggressive.PassiveAggressiveRegressor),
(‘PoissonRegressor’, sklearn.linear_model._glm.glm.PoissonRegressor),
(‘QuantileRegressor’, sklearn.linear_model._quantile.QuantileRegressor),
(‘RANSACRegressor’, sklearn.linear_model._ransac.RANSACRegressor),
(‘RadiusNeighborsRegressor’,
sklearn.neighbors._regression.RadiusNeighborsRegressor),
(‘RandomForestRegressor’, sklearn.ensemble._forest.RandomForestRegressor),
(‘RegressorChain’, sklearn.multioutput.RegressorChain),
(‘Ridge’, sklearn.linear_model._ridge.Ridge),
(‘RidgeCV’, sklearn.linear_model._ridge.RidgeCV),
(‘SGDRegressor’, sklearn.linear_model._stochastic_gradient.SGDRegressor),
(‘SVR’, sklearn.svm._classes.SVR),
(‘StackingRegressor’, sklearn.ensemble._stacking.StackingRegressor),
(‘TheilSenRegressor’, sklearn.linear_model._theil_sen.TheilSenRegressor),
(‘TransformedTargetRegressor’,
sklearn.compose._target.TransformedTargetRegressor),
(‘TweedieRegressor’, sklearn.linear_model._glm.glm.TweedieRegressor),
(‘VotingRegressor’, sklearn.ensemble._voting.VotingRegressor)]
全てのregressorを試す自作関数
k-foldクロスバリデーション入りです。この関係で、cvは2以上にしないとエラーがでます。評価関数は、mean absolute errorを使っていますが必要に応じて直してください。
def apply_all_regressor(x,y,cv=3):
"""
apply all regressors in sklearn with k-fold cross validation
cv should be greater than or equal to 2
Args:
x (_type_): independent variable
y (_type_): target variable
cv (int, optional): how many folds. Defaults to 3.
"""
import time
from sklearn.utils import all_estimators
from sklearn.metrics import mean_absolute_error
results_df = pd.DataFrame(columns=["model_name","score","timeElapsed","cv"])
from sklearn.model_selection import KFold
kf = KFold(n_splits=cv,shuffle=True)
for i, (train_index, test_index) in enumerate(kf.split(X=x)):
x_train = x[train_index]
x_test = x[test_index]
y_train = y[train_index]
y_test = y[test_index]
for model in all_estimators(type_filter="regressor"):
results_df.to_csv("results.csv",index=False)
time_start = time.time()
try:
thismodel = model[1]()
print(model[0])
try:
thismodel.fit(x_train,y_train)
result = mean_absolute_error(y_true=y_test,
y_pred=thismodel.predict(x_test))
print(result)
time_spent = time.time()-time_start
results_df = pd.concat([results_df,
pd.DataFrame({"model_name":model[0],
"score":[result],
"timeElapsed":[time_spent],
"cv":[i]})],
axis=0)
except:
print("fitting error")
results_df = pd.concat([results_df,
pd.DataFrame({"model_name":model[0],
"score":["fittingError"],
"timeElapsed":[0],
"cv":[i]})],
axis=0)
except:
print("instanciating error")
results_df=pd.concat([results_df,
pd.DataFrame({"model_name":model[0],
"score":["instanciatingError"],
"timeElapsed":[0],
"cv":[i]})],
axis=0)
temp = results_df.pivot(index="model_name",columns="cv")
temp = temp.reset_index()
temp.columns = temp.columns.values
temp.columns = ["model_name"]+temp.columns[1:].to_list()
results_df["mean_score"] = pd.to_numeric(results_df["score"],errors="coerce")
results_df["mean_time"] = pd.to_numeric(results_df["timeElapsed"],errors="coerce")
results_df = (results_df.groupby("model_name"))[["mean_score","mean_time"]].agg("mean")
results_df = results_df.sort_values(by="mean_score")
results_df = results_df.reset_index()
results_df = results_df.merge(temp,on=["model_name"])
results_df.to_csv("results_regressors.csv",index=False)
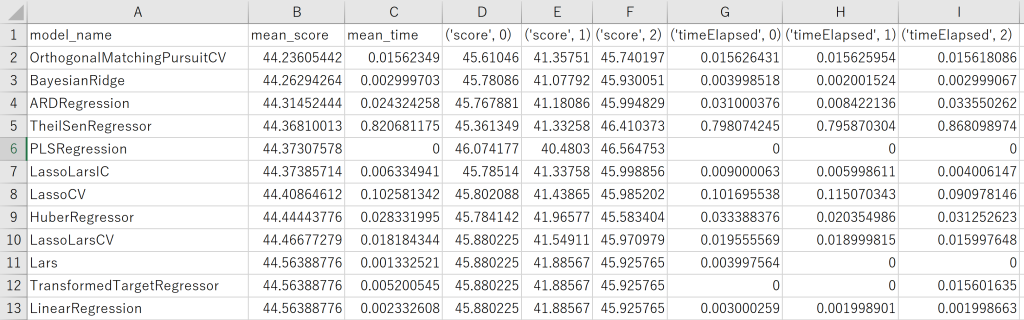
print("Done!")試しにsklearnの糖尿病のデータセットを使ってみます。
使い方は、apply_all_regressor(説明変数、目的変数、kフォルドクロスバリデーションの回数)です。
import pandas as pd
from sklearn.datasets import load_diabetes
x,y = load_diabetes(return_X_y=True)
apply_all_regressor(x,y,cv=3)結果は、csvで出力されます。