
以前の続きです。ハンガリーにおけるchikenpox(水疱瘡)のデータを使って、BUTAPESTにおける患者数の3か月分の予想を行っています。今まではAutoMLを使って予測してきました。今回は、LSTM(Long Short Term Memory)を使って予測したいと思います。
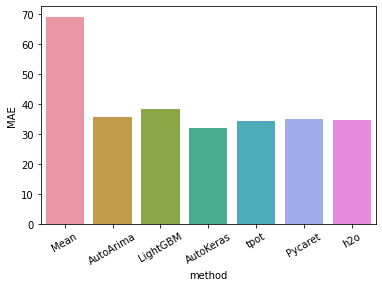
Long short-term memory(LSTM)
Neural Netの亜種です。LSTMは、時系列データに適したニューラル・ネットワークの一種です。通常のニューラルネットに以前の状態を記憶するレイヤーが追加されています。
keras(tensorflow)で実装します。なんといっても、LSTMに学習させるデータの形を作るまでが大変です。tensorflowのチュートリアルは鬼のようにデータ加工の部分が長くて辛いです。
ハンガリーのchikenpoxのデータを加工していきます。
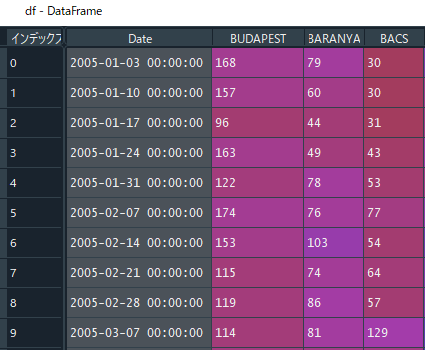
まずはどんな形をしているか見てみます。
df = pd.read_csv('hungary_chickenpox.csv')
df["Date"] = pd.to_datetime(df["Date"],format='%d/%m/%Y')このBUDAPESTの数を予想したいと思います。
最終的にどういう形にするのかというと、numpy ndarrayの形で(record数, lag, feature数)の形にします。featuresは、1変数だと複数のlagを含んでも1です。
lagの配列を作成
まずラグ(shift)を含んだ、numpy ndarrayを作成する関数を自作します。使い方は、X,Y = windowgenerator(データフレーム,目的変数,ラグ数)です。Xは、時点T-1、T-2、、です。Yは時点Tです。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('hungary_chickenpox.csv')
df["Date"] = pd.to_datetime(df["Date"],format='%d/%m/%Y')
def windowgenerator(dataframe,target,shift):
Y = np.array(df[target])
Y = np.expand_dims(Y,axis=1)
for i in reversed(range(1,shift+1)):
if i == (shift):
X = Y[(shift-i):(len(Y)-i), :]
else:
X2 = Y[(shift-i):(len(Y)-i), :]
X = np.concatenate([X,X2],axis=1)
Y = Y[shift:len(dataframe), :]
return X,Y
X,Y = windowgenerator(df,"BUDAPEST",3)X[0:5]をみます。
array([[168, 157, 96],
[157, 96, 163],
[ 96, 163, 122],
[163, 122, 174],
[122, 174, 153]], dtype=int64)
Y[0:5]を見ます。
array([[163],
[122],
[174],
[153],
[115]], dtype=int64)
Standardize
配列から平均を引いて、強制的に平均を0にします。その後、SDで割って強制的にSDを1の配列にします。sklearnの関数を使っておけば後で変更前に戻すことが可能です。
もし、StandardizationではなくNormalization(強制的に0から1の範囲にする)をしたいという場合にはコメントアウトしたところのコードを使います。
# Standardization ( value - mean ) / SD
from sklearn.preprocessing import StandardScaler
stand_x = StandardScaler().fit(X)
X = stand_x.transform(X)
stand_y = StandardScaler().fit(Y)
Y = stand_y.transform(Y)
'''
#Normalization 0 ~ 1
from sklearn.preprocessing import MinMaxScaler
norm_x = MinMaxScaler().fit(X)
X = norm_x.transform(X)
norm_y = MinMaxScaler().fit(Y)
Y = norm_y.transform(Y)
'''Kerasでモデルを作成
モデルを作成します。と、その前にnumpy ndarrayの形を3次元に拡張しておきます。(record数, lag, feature数)。
3~7行は私のPCでなぜか必要になってしまったGPUを使うための呪文です。
X = np.expand_dims(X,axis=2) # ( , ) -> ( , ,1)
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
from tensorflow import keras
from tensorflow.keras.layers import Input,LSTM,Dense
from tensorflow.keras.optimizers import Adam
inputs = Input(shape=(X.shape[1],X.shape[2]))
lstm_out = LSTM(16)(inputs)
outputs = Dense(1)(lstm_out)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=Adam(learning_rate=0.01),
loss= "mse",
metrics = "mae")
model.summary()Layer (type) Output Shape Param # input_14 (InputLayer) [(None, 3, 1)] 0 lstm_18 (LSTM) (None, 16) 1152 dense_20 (Dense) (None, 1) 17 Total params: 1,169 Trainable params: 1,169 Non-trainable params: 0
後記:以下のコードは、改善点すべき点があります。
1未来ずつ、3か月分(13レコード分)を予想します。
# forecast each 1 step (in total 13 records)
result = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true"])
last13 = len(X)-13
last = len(X)
for i in range(last13,last):
# train, val, testデータを定義
X_train = X[:i, :, :]
Y_train = Y[:i, :]
X_test = X[i:i+1, :, :]
Y_test = Y[i:i+1, :]
model.fit(X_train, Y_train,
validation_split=0.1,
epochs=60,
verbose=0)
pred = model.predict(X_test)
result.iloc[i-(last13),0] = float(pred[0,0])
result.iloc[i-(last),1] = Y_test[0,0]
result["pred"] = stand_y.inverse_transform(np.expand_dims(result["pred"],axis=1))
result["true"] = stand_y.inverse_transform(np.expand_dims(result["true"],axis=1))
result["mae"] = abs(result["true"]-result["pred"])
result["mae"].mean()実行するたびに結果が異なるので安定しませんが、いいときはMAE33.1を出しました。AutokerasのMAE31ですのでAutoMLにはなかなか勝てませんね。
後記:上記コードは、モデルのweightをリセットすることなく繰り返し学習させています。そのため、過学習を起こしてしまっていました。for loopの毎にweightをリセットする必要があります。そのため以下のコードが必要になります。
for loop外で初期weightを保存 weights = model.get_weights()
for loop内で重みを再ロード model.set_weights(weights)
重みを再ロードすることで重みを初期化します。
autokerasのモデルはget_weightsができないので、いったんh5ファイルで保存して、再度tensorflowモデルとして読み込む必要があります。同じモデルですが、こうすることでget_weightsができるようになります。
result_AK = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true_diff"])
last30 = len(df4)-13
last = len(df4)
# Evaluate the best model with testing data.
# Evaluate the best model with testing data.
model_autokeras = ak_model.export_model()
model_autokeras.save("/content/drive/MyDrive/autokeras_model_reset.h5")
from tensorflow.keras.models import load_model
ak_model2 = load_model("/content/drive/MyDrive/autokeras_model_reset.h5",custom_objects=ak.CUSTOM_OBJECTS)
weights = ak_model2.get_weights()
for i in range(last30,last):
X_train = (df4 >> select(~X["next"])).iloc[0:i]
y_train = (df4 >> select(X["next"])).iloc[0:i]
X_test = (df4 >> select(~X["next"])).iloc[i:i+1]
y_test = (df4 >> select(X["next"])).iloc[i:i+1]
ak_model2.set_weights(weights)
ak_model2.fit(x = X_train, y= y_train,
epochs = 100,
validation_split=0.1)
pred = ak_model2.predict(X_test)
result_AK.iloc[i-(last30),0] = float(pred)
result_AK.iloc[i-(last30),1] = y_test.values[0,0]さらにチェックポイントを作成し、学習中の一番いいモデルを使って予測するコードは以下のようにします。
from tensorflow.keras.callbacks import ModelCheckpoint
import os
import tensorflow as tf
result_AK = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true_diff"])
last30 = len(df4)-13
last = len(df4)
# Evaluate the best model with testing data.
model_autokeras = ak_model.export_model()
model_autokeras.save("/content/drive/MyDrive/autokeras_model_reset.h5")
from tensorflow.keras.models import load_model
ak_model2 = load_model("/content/drive/MyDrive/autokeras_model_reset.h5",custom_objects=ak.CUSTOM_OBJECTS)
weights = ak_model2.get_weights()
for i in range(last30,last):
X_train = (df4 >> select(~X["next"])).iloc[0:i]
y_train = (df4 >> select(X["next"])).iloc[0:i]
X_test = (df4 >> select(~X["next"])).iloc[i:i+1]
y_test = (df4 >> select(X["next"])).iloc[i:i+1]
ak_model2.set_weights(weights)
checkpoint_path = "training/cp-{epoch:04d}.ckpt"
checkpoint_dir = os.path.dirname(checkpoint_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_path,
verbose=1,
save_weights_only=True,
period=5)
ak_model2.save_weights(checkpoint_path.format(epoch=0))
ak_model2.fit(x = X_train, y= y_train,
epochs = 100,
validation_split=0.1,
callbacks = [cp_callback])
latest = tf.train.latest_checkpoint(checkpoint_dir)
ak_model2.load_weights(latest)
pred = ak_model2.predict(X_test)
result_AK.iloc[i-(last30),0] = float(pred)
result_AK.iloc[i-(last30),1] = y_test.values[0,0]