タイトル強め、結果弱めです。
以前の続きです。ハンガリーにおけるchikenpox(水疱瘡)のデータを使って、BUTAPESTにおける患者数の3か月分の予想を行っています。今まではAutoML、LSTM、CNNを使って予測してきました。
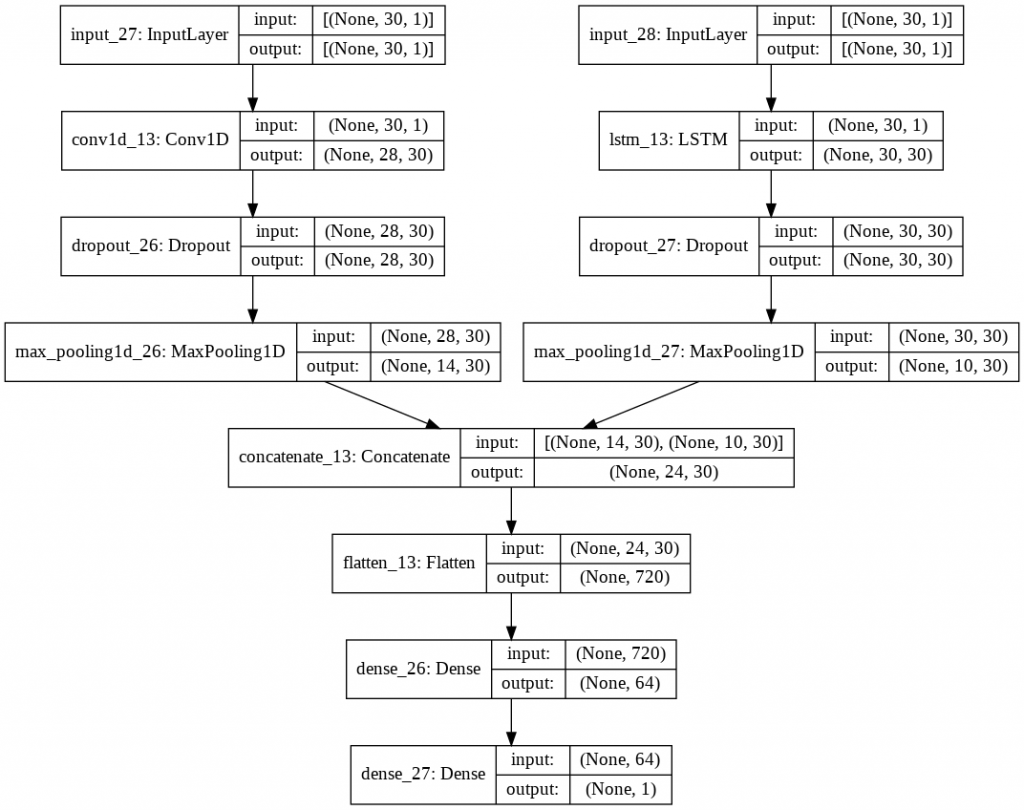
Kerasのfunctional APIを使えば、異なるインプットから途中で層を結合したりすることができます。今回は、LSTMとCNNを結合して時系列データの予測をしてみたいと思います。
インプット① → LSTM → Dense ← CNN ← インプット②
結合するときの難しさは、numpy ndarrayの次元を調整するところです。layerを通るたびに変化していくnumpy ndarrayの構造を頭の中で再現するのが難しいと感じています。
インプット①とインプット②は異なるものでいいのですが、めんどくさいのでインプット①とインプット②を同じものとします。インプット①はLSTMで処理し、インプット②をCNNで処理し、それぞれ有益な特徴を取得してきます。その後、Dense層でアウトプットまでつないでいきます。
データ処理
ブタペストのchikenpoxの患者数のデータについて、過去30レコード分を1列としたデータを生成しています。Xは現在~30過去、Yは1未来です。
詳細は、以前の記事を参考にしてください。同じ処理を詳しく記載しています。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('hungary_chickenpox.csv')
df["Date"] = pd.to_datetime(df["Date"],format='%d/%m/%Y')
def windowgenerator(dataframe,target,shift):
Y = np.array(df[target])
Y = np.expand_dims(Y,axis=1)
for i in reversed(range(1,shift+1)):
if i == (shift):
X = Y[(shift-i):(len(Y)-i), :]
else:
X2 = Y[(shift-i):(len(Y)-i), :]
X = np.concatenate([X,X2],axis=1)
Y = Y[shift:len(dataframe), :]
return X,Y
X,Y = windowgenerator(df,"BUDAPEST",30)
# Standardization ( value - mean ) / SD
from sklearn.preprocessing import StandardScaler
stand_x = StandardScaler().fit(X)
X = stand_x.transform(X) # (492,30) -> (492,30,1)
stand_y = StandardScaler().fit(Y)
Y = stand_y.transform(Y)
X = np.expand_dims(X,axis=2)この時点でXの次元は(492, 30, 1)、Yの次元は(492, 1)です。
Keras
以下が、Keras構造を作っているところです。sequential モデルと違うのは、input層を定義して、そのアウトプットを次の層のインプットとして明記するところです。電源の延長ケーブルをつないでいるみたいですね。
最初の5行は私のPCでGPUを使うために必要となってしまった呪文です。
CNNパートは、Conv1D→Maxpooling1Dをしています。
LSTMパートは、LSTM→Maxpooling1Dをしています。
Fusionパートは、くっつけて(Concatenate)一列(flatten)にしています。
Lastパートは、Dense層を2層くっつけています。
concatenateをする際には、(outer most dimension , 呼び方不明な次元 , inner most dimension)の 呼び方不明な次元か、もしくはinnner most dimensionの数を合わせないといけません。その数があっている軸ではない方をConcatenate(axis=〇)で設定します。
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
from tensorflow import keras
from tensorflow.keras.layers import Input,LSTM,Dense,Concatenate
from tensorflow.keras.layers import Dropout,Conv1D,MaxPool1D,Flatten
from tensorflow.keras.optimizers import Adam
################ CNN part ####################
inputs = Input(shape=(X.shape[1],X.shape[2]))
conv1th = Conv1D(filters=30,kernel_size=3)(inputs)
drop1 = Dropout(0.2)(conv1th)
maxpool = MaxPool1D(pool_size=2)(drop1)
################ CNN part ####################
################ LSTM part ####################
inputs2 = Input(shape=(X.shape[1],X.shape[2]))
lstm = LSTM(30,return_sequences = True)(inputs2)
drop2 = Dropout(0.2)(lstm)
maxpool2 = MaxPool1D(pool_size=3)(drop2)
################ LSTM part ####################
################ fusion part ####################
conc = Concatenate(axis=1)([maxpool, maxpool2])
flat = Flatten()(conc)
################ fusion part ####################
################ last part ####################
dense1 = Dense(64,activation="relu")(flat)
outputs = Dense(1)(dense1)
################ last part ####################
################ model compile part ####################
model = keras.Model(inputs=[inputs,inputs2], outputs=outputs)
model.compile(optimizer=Adam(learning_rate=0.01),
loss= "mse",
metrics = "mae")学習と予測を行います。未来3か月分(13レコード分)を予測します。一気に予測するのではなく、1未来ごとに予測していきます。つまり最終レコードを予測する時点ではtrainデータに最終レコード以外のすべてのデータが入っています。
NNは結果が安定しないので5回勉強させた結果を求めます。まずはコード。
result_list = []
weights = model.get_weights()
early = keras.callbacks.EarlyStopping(monitor='val_loss',
patience=5,
verbose=1,
mode='auto')
cp_callback = keras.callbacks.ModelCheckpoint(
filepath="training_keras/checkpoint",
verbose=1,
monitor="val_loss",
save_weights_only=True,
save_best_only=True,
period=10)
for k in range(1,6):
# forecast each 1 step (in total 13 records)
result = pd.DataFrame(0,
index=np.arange(13),
columns=["pred", "true"])
last13 = len(X)-13
last = len(X)
for i in range(last13,last):
X_train = X[:i, :, :]
Y_train = Y[:i, :]
X_test = X[i:i+1, :, :]
Y_test = Y[i:i+1, :]
model.set_weights(weights)
history = model.fit([X_train,X_train],
Y_train,
validation_split=0.1,
epochs=100,
verbose=2,
callbacks=[cp_callback,early])
model.load_weights("training_keras/checkpoint")
pred = model.predict([X_test,X_test])
### visualization of the train test loss ###
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
### visualization of the train test loss ###
result.iloc[i-(last13),0] = float(pred[0,0])
result.iloc[i-(last),1] = Y_test[0,0]
# calculate MSE after inverse transformation
result["pred"] = stand_y.inverse_transform(np.expand_dims(result["pred"],axis=1))
result["true"] = stand_y.inverse_transform(np.expand_dims(result["true"],axis=1))
result["mae"] = abs(result["true"]-result["pred"])
result_list.append(result["mae"].mean())early stoppingを入れた方がいい理由
early stoppingは設定した指標の改善がない場合に、学習をやめます。これ以上勉強しても過学習が進んでいくだけで、時間の無駄ということです。まず、early stoppingの設定をみます。
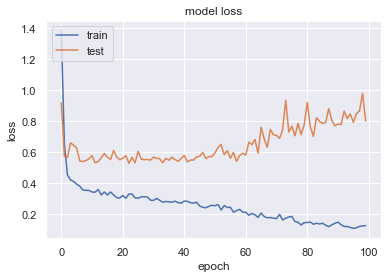
ためしに、earlystoppingなしの場合のグラフをみます。100epocをきっちり勉強しますが、60エポックあたりで過学習が起こっています。これ以上勉強するのは時間の無駄になりますので、学習を辞めたいところです。また、既に10エポックくらいからloss(mse)が改善していませんので、10エポックくらいで学習を辞めてもいいと思われます。
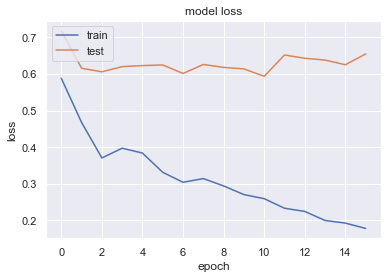
今度は、earlystoppingを入れた場合です。
early = keras.callbacks.EarlyStopping(monitor=’val_loss’,
patience=5,
verbose=1,
mode=’auto’)
monitorは、どの数値を持って判断するか。この場合は、validationのlossの値を見ます。patienceは数値が上がらなくなってからどの未来の時点まで我慢して勉強するかです。verboseはコンソールに出てくる説明量です。modeはmonitorの定義によって、数値が上に行ったら改善(accuracy)なのか悪化なのか(mse)異なりますがそれを自動で判定してくれます。
下の図だと10エポックからtestのlossの数値が改善していません。5エポック我慢して勉強しますが、改善がみられないので計算をやめています。
checkpointを入れた方がいい理由
チェックポイントは、学習の途中のweightの重さを保存することができます。学習の途中で出会った最高と思われるモデルを呼び出して予想に使うことができます。学習終了時に最高のモデルであるわけではありません。early stoppingを使えば過学習しきったモデルになってしまうのは防げますが、stop時点が最高とは限りません。上の図だと、エポック10の時点が最高のモデルだと思われます。そのため、その時のweightを使うのが一番正確なモデルです。
cp_callback = keras.callbacks.ModelCheckpoint(
filepath=”training_keras/checkpoint”,
verbose=1,
monitor=”val_loss”,
save_weights_only=True,
save_best_only=True)
これがおすすめ設定です。最高のモデルしか保存されません。
For loopでkerasの学習をさせる際の注意点
for loopの際にweightをリセットしないと、for loopの前のイタレーションで学習した重みを使ってさらに学習してしまうので、過学習が起きてしまいます。そのため、for loopに入る前に初期化したweightを保存し、for loop内でイテレーション毎にその重みを再ロードします。
結果
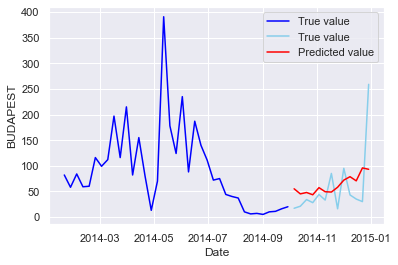
平均MAE40くらいでした。autokerasの結果の方(31)がいいですし、LSTM単独CNN単独のほうが34くらいだったので良かったです。複雑なことやればいいってもんじゃないですね、残念!
グラフ